


Vertica - Execute
The Vertica - Execute Snap enables you to execute SQL statements in a Vertica database. Tables can be created and dropped with this Snap. SELECT queries can also be executed. This Snap works only with single queries.
- This is a Write-type Snap.
 Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
None.
Behavior Change
If the input view is not defined and the Pass through field is selected, the Snap sends an empty input document to the output view when the input view is not defined.
Supported Accounts
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input |
This Snap has at most one document input view. If the input view is defined, then the WHERE clause can substitute incoming values for a given expression. |
|
| Output |
This Snap has at most one document output view. |
|
| Error |
This Snap has at most one document error view and produces zero or more documents in the view. Warning: Database Write Snaps output all records of a batch (as configured in your account settings) to the error view if the write fails during batch processing.
|
Snap settings
- Expression icon (
 ): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value.
): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Description |
|---|---|
| Label
|
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Vertica Execute Example: Vertica Execute |
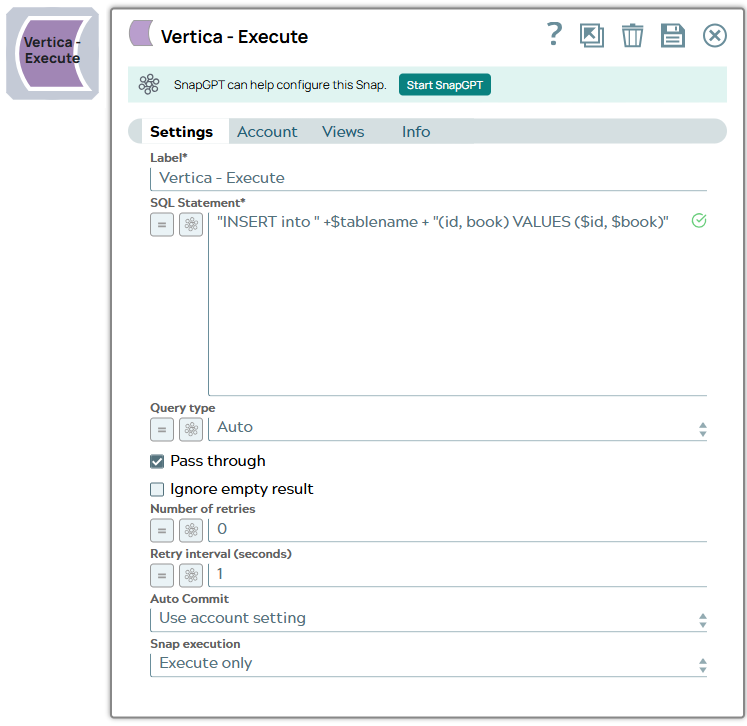
| SQL statement
|
Required. Specify the SQL statement to execute on the server. There are two possible scenarios that you encounter when working with SQL statements in SnapLogic. You must understand the following scenarios to successfully execute your SQL statements: Scenario 1: Executing SQL statements without expressions If the expression toggle of the SQL statement field is not selected:
Additionally, the JSON path is allowed only in the WHERE clause. If the SQL statement starts with SELECT (case-insensitive), the Snap regards it as a select-type query and executes once per input document. If not, it regards it as write-type query and executes in batch mode. Scenario 2: Executing SQL queries with expressions If the expression toggle of the SQL statement field is selected:
Note: Table name and column names must not be provided as bind parameters. Only values can be provided as bind parameters. Note: We recommend you to add a single query in the SQL Statement field. Known issue: When the SQL statement property is an expression, the pipeline parameters are shown in the suggest, but not the input schema. Important notes:
Warning: Single quotes in values must be escaped Any relational database (RDBMS) treats single quotes ( For example:
Default value: N/A |
| Query type
|
Select the type of query for your SQL statement (Read or Write). When Auto is selected, the Snap tries to determine the query type automatically. If the execution result of the query is not as expected, you can change the query type to Read or Write. Default value: Auto Example: Read |
| Pass through
|
Select this checkbox to pass the output view under the key 'original'. This property applies only to the Execute Snaps with SELECT statement. Default value: Selected |
| Ignore empty result
|
If selected, no document will be written to the output view when a SELECT operation does not produce any result. If this property is not selected and the Pass through property is selected, the input document will be passed through to the output view. Default value: Not selected |
| Number of retries
|
Specify the maximum number of retry attempts the Snap must make in case of network failure. When you set the Number of retries to more than 0, the Snap generates duplicate records when the connection is not established. To prevent duplicate records, we recommend that you follow one of the following:
Default value: 0 Example: 2 |
| Retry interval (seconds)
|
Specify the maximum resting time in seconds between subsequent retries. Default value: 1 Example: 2 |
| Auto commit
|
Select one of the options for this property to override the state of the Auto commit property on the account. The Auto commit at the Snap level has three values: True, False, and Use account setting. The expected functionality for these modes are:
Note: 'Auto commit' may be enabled for certain use cases if PostgreSQL jdbc driver is used in either Redshift, PostgreSQL or generic JDBC Snap. But the JDBC driver may cause out of memory issues when Select statements are executed. In those cases, "Auto commit" in Snap property should be set to 'False' and the Fetch size in the "Account setting" can be increased for optimal performance. Note: DDL statements may auto-commit even if the transaction auto-commit mode is off. We recommend that you isolate DDL statements in a separate pipeline and turn on the Auto commit property. Default value: Use account setting |
| Snap Execution
|
Choose one of the three modes in which the Snap executes. The available options are: Validate & Execute: Performs limited execution of the Snap and generates a data preview during pipeline validation. Subsequently, performs full execution of the Snap (unlimited records) during pipeline runtime. Execute only: Performs full execution of the Snap during pipeline execution without generating preview data. Disabled: Disables the Snap and all Snaps that are downstream from it. Default value: Execute only Example: Validate & Execute |