


Heating load prediction
This pipeline demonstrates training a model to predict the heating load of a building. The regression algorithm is selected based on the algorithm evaluation in the Cross Validator (Regression) Snap's example. The input dataset contains various features of the building that influence its heating load.

-
Configure the Trainer (Regression) Snap to train the model for the dataset.
The Trainer (Regression) Snap is configured with the regression algorithm and its parameters, as evaluated in the Cross Validator (Regression) Snap.
Trainer (Regression) Snap Configuration Trainer (Regression) Snap Output 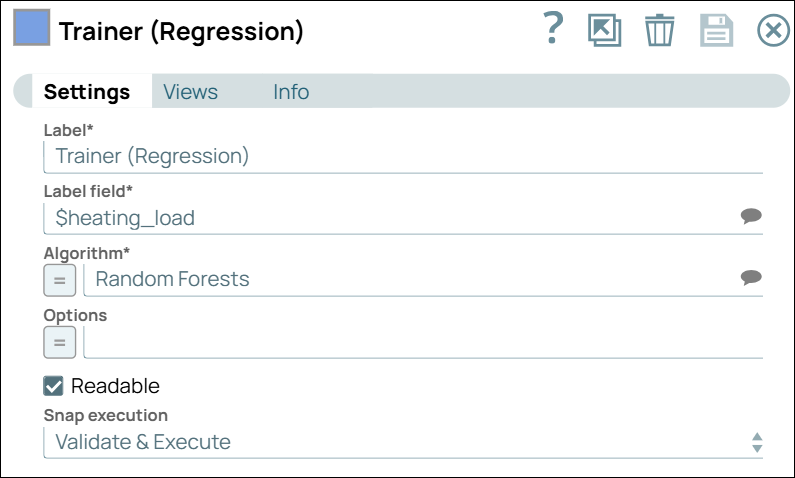
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.