


Weight balance classification
This pipeline demonstrates training a model to predict whether a weighing scale is balanced. The classification algorithm is selected based on the algorithm evaluation in the Cross Validator (Classification) Snap's example. The input dataset depicts the weight on each side of the scale and the side's distance from the floor.

-
Configure the Trainer (Classification) Snap to train the model for the dataset.
The classification algorithm was evaluated in the Cross Validator (Classification) Snap. The Trainer (Classification) Snap is configured with the same settings to train the model.
Trainer (Classification) Snap Configuration Trainer (Classification) Snap Output 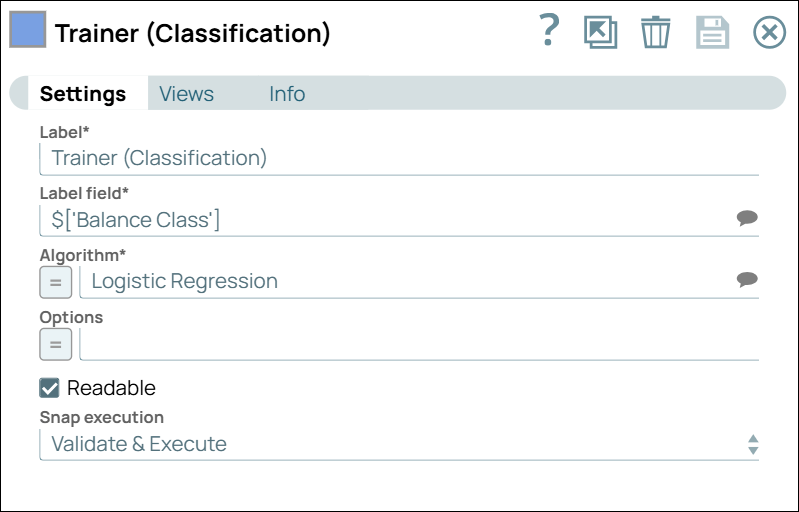
Note: The model generated by the Trainer (Classification) Snap is written into a file using the File Writer Snap, which is configured as shown below. This model can then be used to predict the Balance Class for an unlabeled dataset.
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.