


How to use AutoSync
How to open AutoSync and prepare to create a data pipeline.
SnapLogic AutoSync data pipelines synchronize data between source and destination endpoints. Before creating a data pipeline:
- Gather the credentials and connection information for each endpoint. This information might be stored in the SnapLogic platform already or you can enter it yourself. Learn more.
- Decide which objects, tables, and files to load from source endpoints. Load all of the data required for your use case. Learn more.
- Identify the destination schema. We recommend that each AutoSync data pipeline loads to its own schema to avoid naming conflicts.
- To connect to on-premises endpoints, understand the requirements.
Open the AutoSync dashboard
The AutoSync dashboard provides controls to create, edit, and view data pipelines.
Access AutoSync from the Development section of the waffle menu:
The AutoSync dashboard opens:
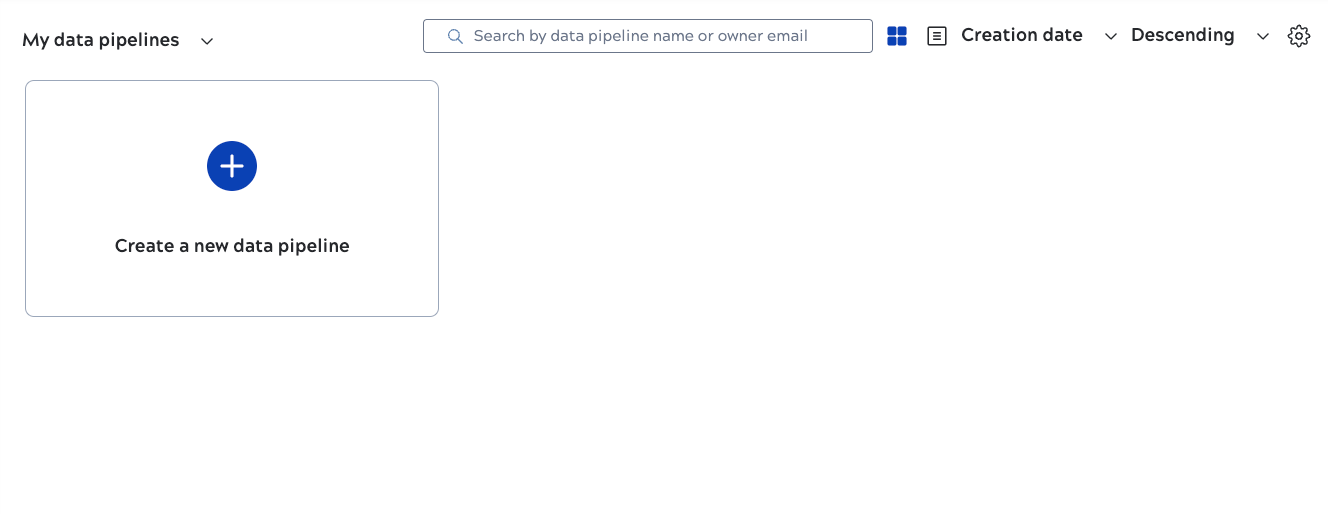
Click Create a new data pipeline and use the wizard to create an AutoSync data pipeline.