


Endpoint schema
The endpoint schema defines the characteristics of a custom endpoint.
The schema.json in the ../src/main/resources/autosyncendoint/src|tgt/customEndpointName folder defines the custom endpoint schema. AutoSync uses this information to validate new or existing credentials that the user selects to connect to the endpoint. The schema specifies:
- The endpoint name, description, type, and visibility.
- The supported Snap account types for credentials.
- The supported load types.
- The menus for selecting schemas, objects, or tables.
The following sections describe the elements and objects in the schema.json file in order. You can start with one of the example files or create your own.
Name and description
The schema.json file starts with the following elements:
name: This should match name of the project subfolder with the custom endpoint implementation.label: The label that displays in the AutoSync wizard.description: A description of the schema.endpoint_type: Eithersourceortarget.visibility: Use a value ofshow.compareCaseInsensitive: Only for target endpoints. Use a value oftrueorfalseto specify whether AutoSync treats identifiers such as schema name, table name, and column name as case-insensitive.
The following shows the SimpleSnowFlake example from the SDK:
"name": "SimpleSnowflake",
"label": "Simple Snowflake",
"description": "Schema to validate a Snowflake Target Endpoint",
"endpoint_type": "target",
"visibility": "show",
"compareCaseInsensitive": false,Supported Snap account types
AutoSync credentials are a specialization of Snap accounts. Depending on the endpoint, multiple types of Snap accounts might be available. For example, you can connect to Box with a Box.com account or a Box service account. AutoSync supports creating one type of account.
The default_class_id field defines the Snap account that users can create in
AutoSync. However, AutoSync can also use Snap accounts created in Designer or Classic manager. The
account_class_ids field optionally specifies those other Snap accounts. Finally, to
simplify credential configuration for AutoSync users, you can expose a subset of available account
fields instead of all of them.
To configure the Snap account types for your custom endpoint, add the following account-related elements to the schema.json file:
default_account_class_id: Defines the Snap account type that users can create in AutoSync. Use the Class FQID from the Info tab of the Snap account. The following example shows the ID for the Hive Database Account: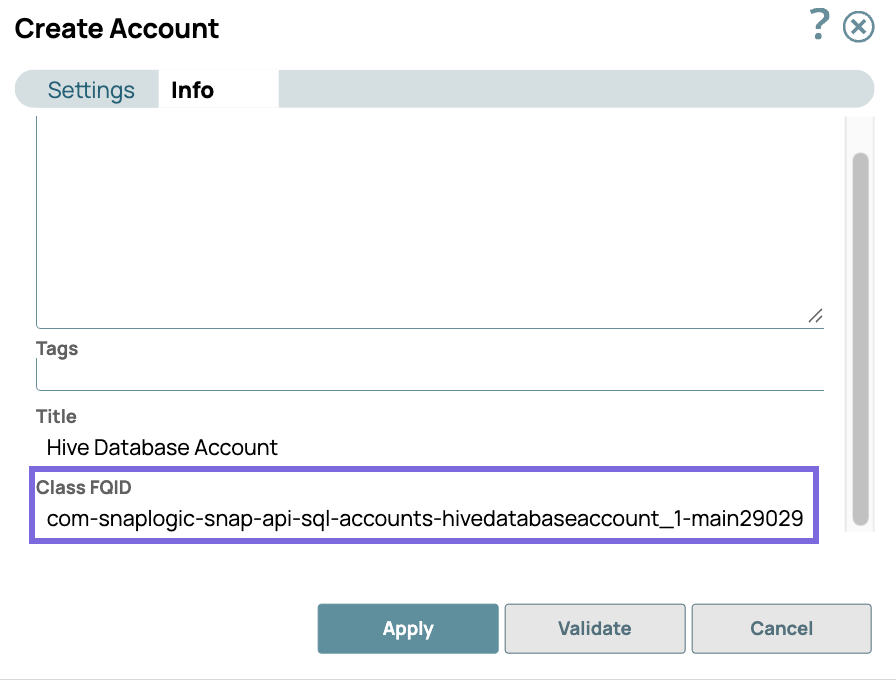
account_class_ids: Repeat the ID of the default account type. Optionally, add other account types to support. This enables AutoSync to use the enumerated account types created in Project Manager or in Designer.visibleFieldsPath: List the fields that will be visible when users save credentials for the endpoint in AutoSync. A field path is of the form:settings.connectionProperties.fieldName.- For
is_oauth, specify whether the default account type uses OAuth for authentication. - For
extraProperties, specify the value for any additional properties, such as a JAR file.
The following example shows the elements for the SimpleSnowflake endpoint from the SDK:
"default_account_class_id": "com-snaplogic-snap-api-sql-accounts-snowflakedatabaseaccount",
"account_class_ids": [
"com-snaplogic-snap-api-sql-accounts-snowflakeazuredatabaseaccount",
"com-snaplogic-snap-api-sql-accounts-snowflakedatabaseaccount",
"com-snaplogic-snap-api-sql-accounts-snowflakes3oauth2account"
],
"visibleFieldsPath": [
"settings.connectionProperties",
"settings.connectionProperties.databaseName",
"settings.connectionProperties.hostname",
"info.label",
"settings.connectionProperties.password",
"settings.connectionProperties.portNumber",
"settings.connectionProperties.username",
"settings.connectionProperties.warehouse"
],
"is_oauth": false,
"extraProperties": [
Supported load types
Refer to Load types for more information about the load types AutoSync supports. In the allowed_load_types object of the schema.json file, enumerate the load types supported by the endpoint:
reloadupsertscd2
The following shows the SimpleSnowFlake example from the SDK:
"allowed_load_types": [
"reload",
"upsert"
],Schema and object or table selection
For endpoints with schemas or similar namespaces, add a class_map and child schema object to the schema.json file. Most source endpoints also require object or table selection.
Schema selection
Both source and target endpoints require the user to select the schema. In a
class_map object, include the following fields for schema selection:
- key: Use schema_selection.schema.
- label: The label that displays in the selector field when the user creates or modifies credentials. Use the terms appropriate for your endpoint. The example SimpleSnowflake endpoint uses Select schema. The example Google Sheets endpoint uses Select spreadsheet.
- priority_index: Determines the order in which fields display in the dialog. The lowest number is first and higher numbers follow in order.
- type: Use dropdown. AutoSync connects to the endpoint and returns a list of schemas for the user to choose from.
- trigger_type: Use schemas.
- required: Use true.
The following shows the SimpleSnowFlake example from the SDK:
"class_map": {
"schema": {
"key": "schema_selection.schema",
"label": "Select schema",
"priority_index": 10,
"type": "dropdown",
"trigger_type": "schemas",
"required": true
},Table or object selection
For source endpoints, users must also select the tables, objects, or files to synchronize. Add the
following fields to the tables object:
key: Useschema_selection.tables.label: Enter the label to appear above the field. For example,Select objects to synchronize.- priority_index: Determines the order in which fields display in the dialog. The lowest number is first and higher numbers follow in order.
type: The field type. For tables, usemultiselect.trigger_type: Use the valuetables.required: Use the valuetrue.
The following shows the SimpleGoogleSheets example for table selection:
"tables": {
"key": "schema_selection.tables",
"label": "Select tables to synchronize",
"priority_index": 40,
"type": "multiselect",
"trigger_type": "tables",
"required": true
},Options
You can add options assuming the Snap account already supports them or you add logic to the pipelines. For example, the SimpleGoogleSheets endpoint adds a Preserve data types checkbox:
"preserve_datatype": {
"key": "schema_selection.extra_params.preserve_datatype",
"label": "Preserve data types",
"priority_index": 50,
"type": "checkbox",
"required": false
}Properties
The fields of the Properties object depend on objects already defined in the file.
For example, the SimpleGoogleSheets source includes:
"properties": {
"schema_selection": {
"type": "object",
"properties": {
"schema": {
"type": "string",
"required": true
},
"tables": {
"type": "array",
"minItems": 1,
"items": {
"type": "object",
"properties": {
"table": {
"type": "string",
"required": true
},
"load_type": {
"type": "string",
"required": true
}
}
},
"default": [
{
"table": "",
"load_type": "reload"
}
]
},
"extra_params": {
"type": "object",
"required": false
}
},
"additionalProperties": false,
"required": true
},
"accounts": {
"type": "array",
"items": {
"type": "string"
},
"required": true
}
}"properties": {
"schema_selection": {
"type": "object",
"properties": {
"schema": {
"type": "string",
"required": true
},
"extra_params": {
"type": "object",
"required": false
}
},
"additionalProperties": false,
"required": true
},
"accounts": {
"type": "array",
"items": {
"type": "string"
},
"required": false
}
}Next, create the pipelines that map endpoint data types to the Common data model. Refer to CDM mapping examples for two examples.