


Partition API
Overview
You can use this Snap to extract raw unstructured data and transform this data into document elements with the Unstructured API. The document elements include—Title, NarrativeText, Table, Image, FigureCaption, and ListItem. Learn more about the supported documents.
- This is a Parse-type Snap.
 Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
None.
Limitations and known issues
None.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has at the most one binary input view. It requires a raw unstructured document as a binary format. | |
| Output | This Snap has at the most one document output view. The output is a structured representation of the document, divided into elements including—Title, NarrativeText, Table, Image, FigureCaption, and ListItem. Table data can be extracted as plain text, HTML, or structured table cells. Images can be extracted as Base64 encoded strings. Only images and PDFs can include image elements in the output. Other document types will include only textual elements, without any image extraction. | |
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
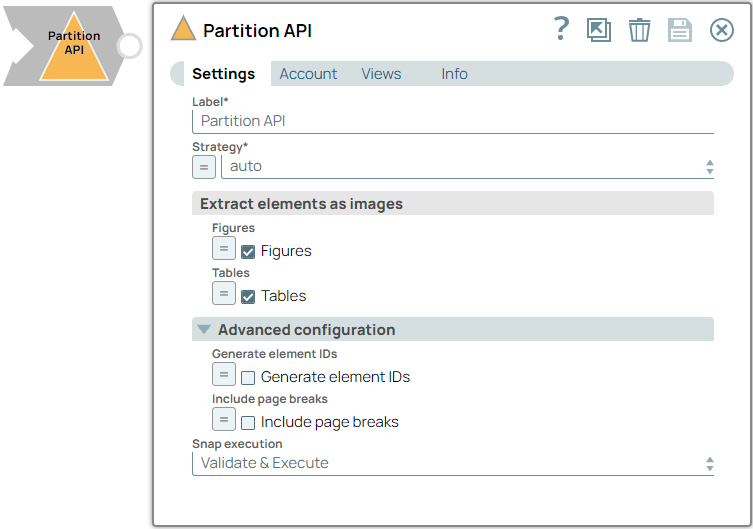
Label
|
String |
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Partition API Example: Extract_Financial_Data_ReportsFY'22 |
| Strategy | Dropdown list/Expression |
Required. Choose the partitioning strategy to use. Available
options include:
Note: This field is only applicable for image and PDF document types and
has no effect on other file types.
Default value: auto Example: fast |
| Extract elements as images |
Appears when you select auto or hi-res in the Strategy dropdown list. Use the following fields to extract the element types as Base64 images. |
|
| Figures | Checkbox/Expression |
Select this checkbox to extract figures as Base64 encoded images.
Note: This field does not support upstream values.
Default status: Selected |
| Tables | Checkbox/Expression |
Select this checkbox to extract tables as Base64 encoded images.
Note: This field does not support upstream values.
Default status: Selected |
| Advanced configuration | Use the following fields to set the advanced configuration to customize the output. | |
| Generate element IDs | Checkbox/Expression |
Select this checkbox to generate UUIDs (Universally Unique Identifiers) from
element IDs to ensure uniqueness. When you deselect this checkbox, the element
text is computed using SHA-256 to create IDs.
Note: This field does not support upstream values.
Default status: Deselected |
| Include page breaks | Checkbox/Expression |
Select this checkbox to include page breaks in the output (if the file type
supports it).
Note: This field does not support upstream values.
Default status: Deselected |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Validate & Execute Example: Execute only |