


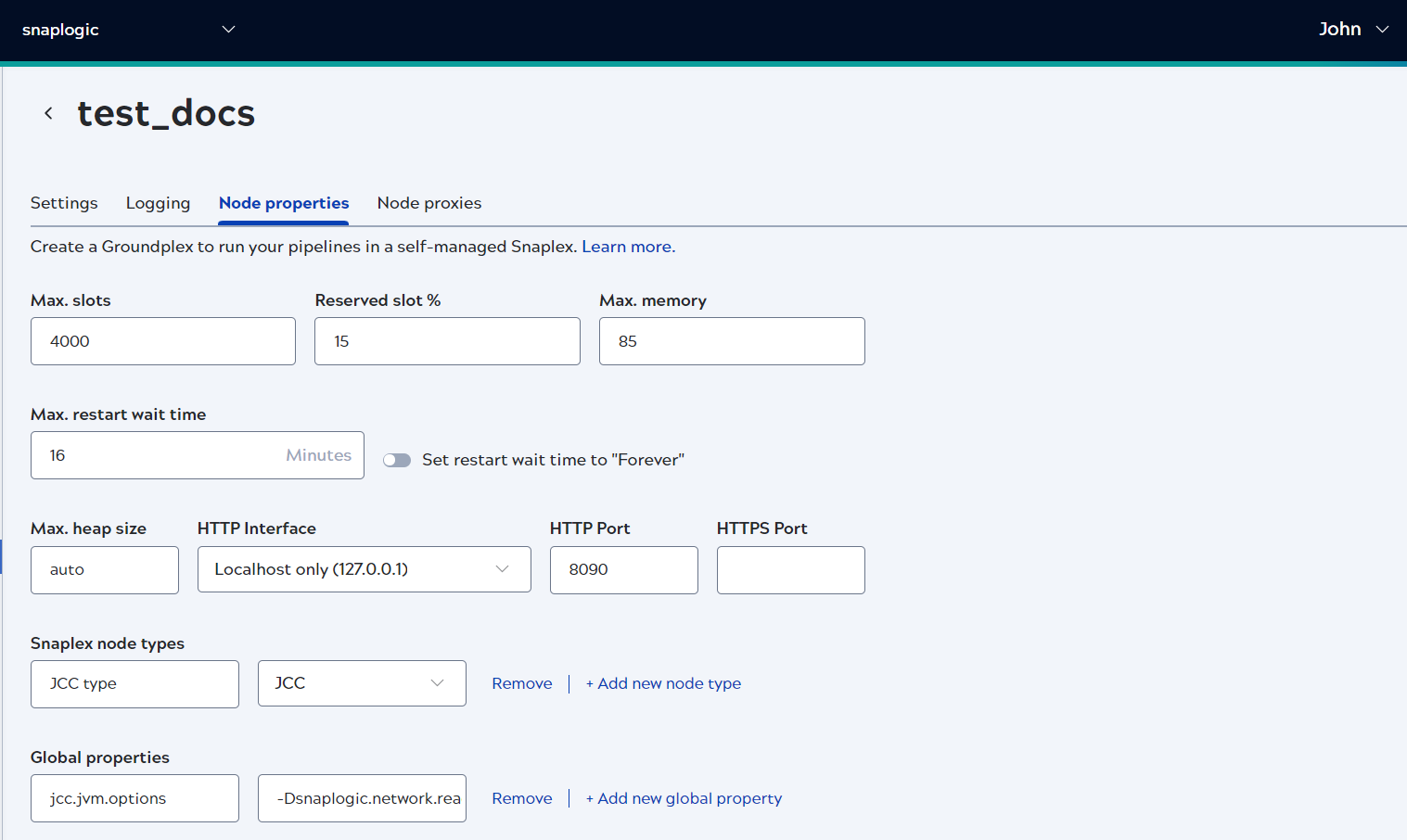
Node properties
Configure node properties for a Groundplex
The Node properties tab in the Snaplex settings controls execution capacity, memory allocation, network interfaces, and JVM configuration for each node.
Node properties fall into the following categories:
- Execution capacity: Max. slots, Reserved slot %, Max. memory
- Restart behavior: Max. restart wait time
- Heap size: Max. heap size
- Network: HTTP Interface, HTTP Port, HTTPS Port
- Node configuration: Snaplex node types, Global properties
In most production environments, these settings are established during initial Groundplex deployment and rarely need to change. Modifying them is typically a developmental or troubleshooting activity.
Execution capacity
The Max. slots, Reserved slot %, and Max. memory properties control how the control plane assigns pipeline executions to nodes in the Snaplex. If all slots on a node are in use, new executions are sent to other nodes in the Snaplex, or held in a Queued state until resources become available.
Max. slots — Each Snap in a pipeline consumes one execution slot. Pipelines can only run on nodes where the number of slots in use is below this threshold; otherwise, normal pipeline executions fail or are placed in a Queued state depending on how they are invoked. For Ultra Task pipelines, the execution is queued. The number of slots in use corresponds to the number of active threads on the node, which you can view in the SnapLogic Monitor.
As a sizing heuristic, allocate 2000 slots per 8 GB of RAM on each node. For nodes with 16 GB of RAM, the default value of 4000 is appropriate. Changes to this setting do not require a restart.
Reserved slot % — Reserved slots are allocated for pipelines or validations executed interactively through the Designer — typically during development and testing. If no slots are reserved, interactive executions can be blocked by long-running pipelines. Pipelines started via Tasks or the Pipeline Execute Snap do not have access to reserved slots. Changes to this setting take effect immediately without a node restart. The default value is 15.
- Set the value higher to reserve more slots for interactive sessions.
- If interactive pipeline building is not a priority, set the value lower to allocate more capacity for automated executions.
Max. memory — When node memory usage reaches this threshold (expressed as a percentage of max heap), no additional pipelines are assigned to that node. Like Reserved slot %, this setting can be updated without restarting the node. The default value is 85.
Restart behavior
Max. restart wait time — The maximum time the monitor process waits before restarting an unresponsive node. Enabling the Set restart wait time to Forever toggle disables the numeric field and prevents automatic restarts. The default value is 15 minutes. Refer to Node initialization alerts for context on node restart scenarios.
Heap size
Max. heap size — Sets the maximum JVM heap size. The default value, auto, lets SnapLogic set the heap size automatically based on available machine memory. For details on auto-sizing tiers and swap memory configuration, refer to Memory management.
Network
HTTP Interface — Controls which network interface the node accepts connections on. Select Localhost only (127.0.0.1) to restrict connections to the local machine, or Any interface (0.0.0.0) to accept connections from any network interface. The default is Localhost only (127.0.0.1).
HTTP Port — The port on which the Snaplex node listens for HTTP connections. The default is 8090 for a JCC node and 8091 for a FeedMaster node.
HTTPS Port — The port on which the Snaplex node listens for HTTPS connections. No default value.
To specify the URL that other nodes use to reach this node — for example,
when the desired address is not available in the
HTTP Interface dropdown — set the
cc_secure_uri JVM option. See Set a specific IP address
for a Groundplex node.
For firewall and port planning, refer to Groundplex requirements: Network.
Node configuration
Snaplex node types — Maps hostnames to node roles (JCC or FeedMaster). Additional entries can be added with + Add new node type.
Global properties — Key/value pairs for internal JVM and JCC configuration options. Do not edit these values without guidance from your CSM. Additional entries can be added with + Add new global property. For examples of common global property use cases, refer to Snaplex configuration for Snaps.
Common Global Properties
- When upgrading a Windows-based Groundplex to use the
slpropzconfiguration file, update the Monitor process by runningjcc.bat update_service. If the Monitor process is not updated, the maximum heap space for the JCC process may be set incorrectly. - By default, if the first run of an Ultra Task fails, SnapLogic attempts to
run the task up to five times. You can customize this retry limit for Ultra
Tasks on a specific Snaplex by modifying the
ultra.max_redelivery_countparameter in the Global properties of your Snaplex.