


Cross Validator (Regression)
You can use this Snap to perform the K-fold Cross Validation on a regression dataset. Cross validation is a technique for evaluating ML algorithms by splitting the original dataset into K equally-sized chunks. K is the number of folds. In each of the K iterations, K-1 chunks are used to train the model while the last chunk is used as a test set. The average error and other statistics are computed to be used to select the most suitable algorithm for the dataset.
Overview
 Transform-type Snap
Transform-type Snap-
 Does not support Ultra Tasks
Does not support Ultra Tasks
Prerequisites
- The data from upstream Snap must be in tabular format (no nested structure).
- This Snap automatically derives the schema (field names and types) from the first document. Therefore, the first document must not have any missing values.
Limitations and known issues
None.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has atmost one input view. | File Reader |
| Output | This Snap has atmost one output view. | File Writer |
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
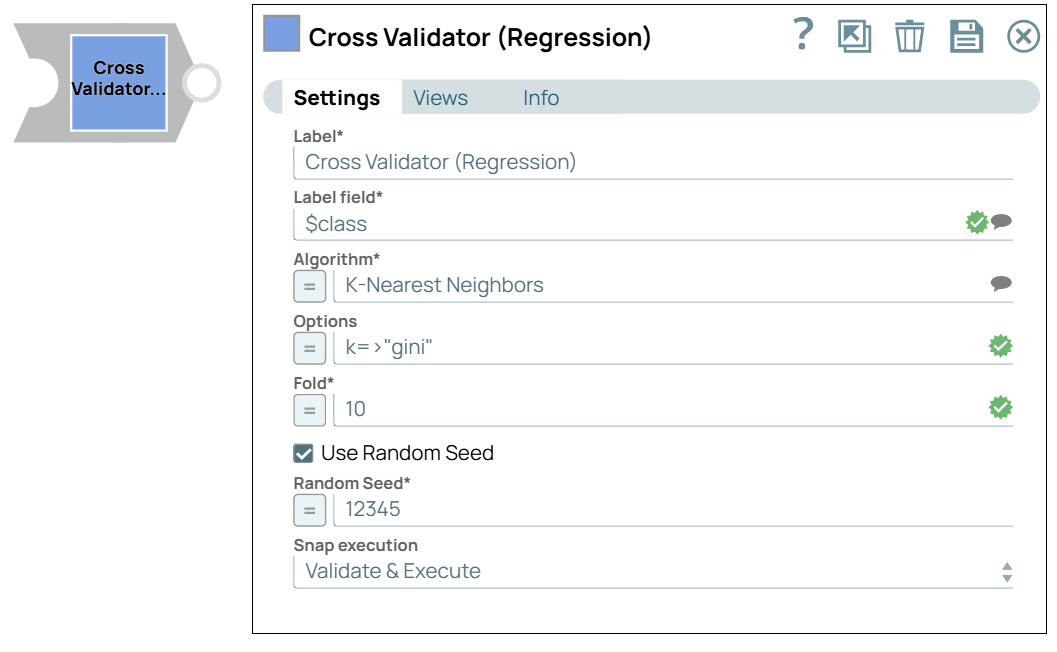
Label
|
String |
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Cross Validator (Regression) Example: Regression customer name |
| Label field | String/Suggestion | Required.Specify the target or class field of
the dataset that the model will use during the training process. This field
represents the expected output values that the model learns to predict based on the
input data. During inference, the model predicts this field as its output. Default value: N/A Example: $class |
| Algorithm | String |
Required. Enter the classification algorithm that builds the model. Default value: K-Nearest Neighbors Example: Naive Bayes |
| Options | String/Expression |
Specify the parameters to configure the selected algorithm. These options may include hyperparameters or specific settings that influence the algorithm's behavior. Default value: N/A Example: max_depth=5, criterion="gini"/> |
| Fold | Integer/Expression | Required. Enter the number of folds for
cross-validation. This determines how the dataset is split for training and testing
during model evaluation. Default value: 5 Example: 10 |
| Use Random Seed | Checkbox | When selected, it ensures reproducibility by setting a fixed random seed for
model training and evaluation. Default status: Deselected |
| Random Seed | Integer/Expression | Required. Specify the number used for initializing the
random number generator to ensure reproducibility in model training. Default value: 12345 Example: 500 |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Validate & Execute Example: Execute only |