


OpenSearch Query
Overview
You can use this Snap to execute a query on the specified OpenSearch index.
- This is a Read-type Snap.
 Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
- A valid account with the required permissions.
Limitations and known issues
None.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has at the most one document input view. The input requires the OpenSearch index and vector name. | Mapper |
| Output | This Snap has at the most one document output view. The Snap retrieves the top matching vectors close to a specific vector in the OpenSearch index and outputs the corresponding mapping for those matching vectors (if required). | Mapper |
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
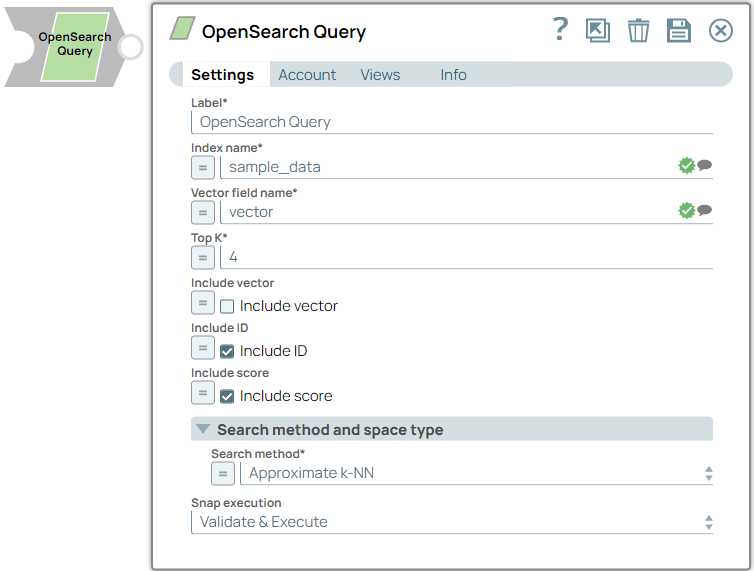
Label
|
String |
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: OpenSearch Query Example: TextSimilarityDocument |
| Index name | String/Expression/ Suggestion |
Required. Specify the name of the OpenSearch index from which you want to query records. Default value: N/A Example: document_embeddings |
| Vector field name | String/Expression/ Suggestion | Specify the name of the vector field. Note: Index
name must be defined to populate the suggestions in this
field.
Default value: N/A Example: embedding_vector |
| Top K | String/Expression | Required. Specify the maximum number of matches to retrieve per query result. This field processes samples exclusively from the top k options for each subsequent token. Default value: 4 Example: 5 |
| Include vector | Checkbox/Expression | Select this checkbox to include the vectors in the response. Note: You can
use the expression enabler to fetch values from pipeline parameters that
evaluate to either true or false. Default status: Deselected |
| Include ID | Checkbox/Expression | Select this checkbox to include the ID in the response. Note: You can use
the expression enabler to fetch values from pipeline parameters that evaluate to
either true or false. Default status: Selected |
| Include score | Checkbox/Expression | Select this checkbox to include the score in the response. Note: You can
use the expression enabler to fetch values from pipeline parameters that
evaluate to either true or
false. Default status: Selected |
| Search method and space type | Choose your k-NN Search method and space type configuration. | |
| Search method | Dropdown list |
Required. Choose the method for obtaining the k-nearest
neighbors from an index of vectors. Available options include:
Default value: Approximate k-NN Example: Painless Extension k-NN |
| Painless extension k-NN function type | Dropdown list |
Appears when you select Painless extension k-NN for the Search method. Required.Choose the painless function type based on your data characteristics and search requirements. Available options include:
Learn more about Function types. Default value: l2Squared Example: cosineSimilarity |
| Script score k-NN space type | Dropdown list |
Appears when you select Script score k-NN for the Search method. Required.Choose the space type based on your data characteristics and search requirements. Available options include:
Learn more about Space type. Default value: l1 Example: innerproduct |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Validate & Execute Example: Execute only |