


How AutoSync handles errors
On the initial run of a data pipeline, AutoSync does a Full load. With the exception of file sources and endpoints that don't support Incremental load, subsequent runs load incrementally, only adding new records and updating changed records. You have the option for some endpoints to use SCD2, which also loads only new and updated records.
AutoSync handles errors differently for full and incremental loads:
- If errors occur during a full load, AutoSync generates an error log and attempts to finish the load. Environment admins (Org admins) can Find error logs for records that failed to load.
- If errors occur during upsert, synchronization fails.
Errors during loading can be caused by many reasons, including:
- Invalid source data.
- Data exceeds size limits of the destination. For example, the number of rows or columns or the size in bytes.
- Names in the source for tables or columns aren't valid for the destination. For example, names with unsupported characters or too many characters.
- When tables have been removed from the source. In this case, AutoSync gives you the option to remove them from the data pipeline and try again.
- When AutoSync detects that a source column has changed from NOT NULL to NULLABLE, and the target endpoint's schema does not support altering nullability, it logs the issue and skips the alteration.

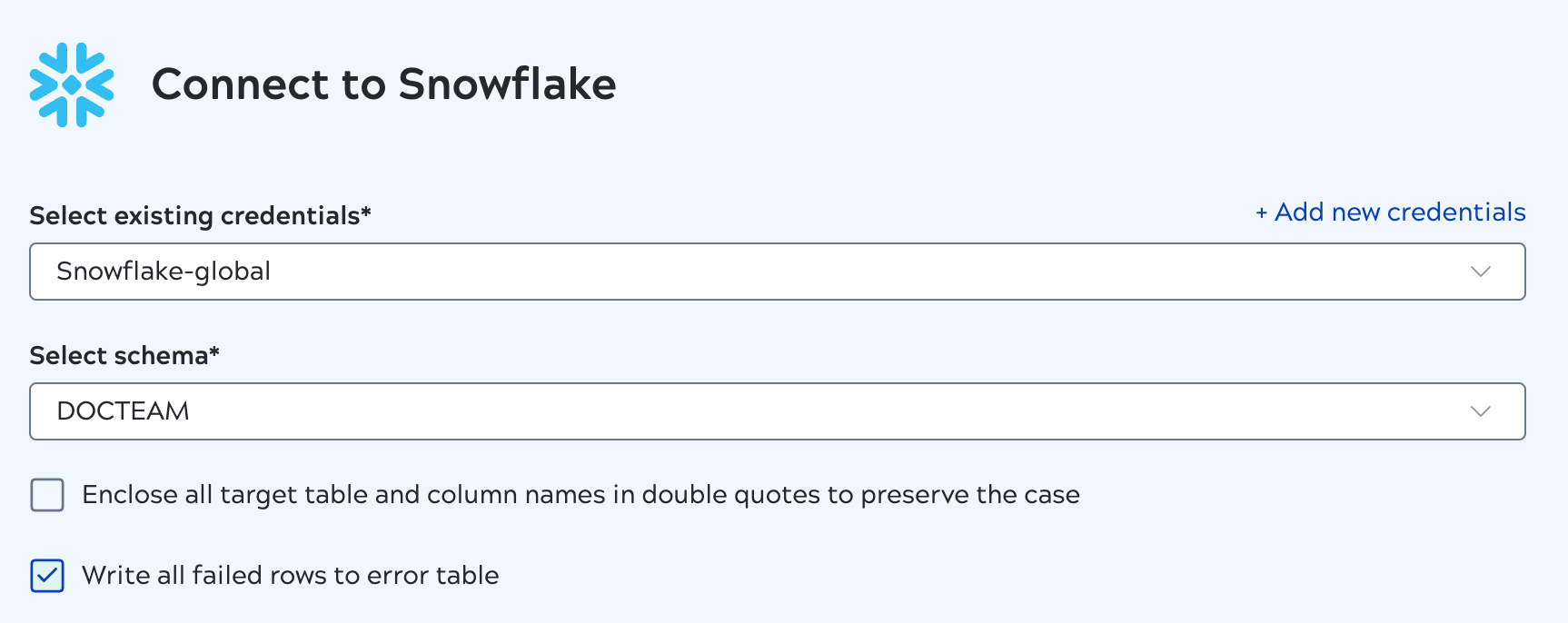
Error tables
For the incremental load type, AutoSync can log errors in a destination table. Error tables are best used during testing and debugging because they have a negative effect on performance.
- The error table name is the table name prepended by
autosync_error_table_. - The first column in the table holds the primary key of the record that failed.
- Columns include:
AUTOSYNC_PRIMARYKEY,LAST_RUN,INTEGRATION_NAME,ERROR_TYPE,ERROR_MSG- If an insert error occurs for a full or an incremental load, the value in the
ERROR_TYPEcolumn isInsert Error. - If an update error occurs for an incremental load, the value in the
ERROR_TYPEcolumn isUpdate Error.
- If an insert error occurs for a full or an incremental load, the value in the
Error table support
- Databricks
- Google BigQuery
- MySQL
- Oracle
- PostgreSQL
- Snowflake
- SQL Server and SQL Server Bulk Load
Stopping a running data pipeline
You can stop a running data pipeline if necessary. This clears all statistics on loaded tables and records from the details panel.
Stopping a data pipeline during execution can cause data corruption in the target. If it's necessary to stop a data pipeline configured with the Full load or Incremental load type, we recommend doing a Full load on the next run. A Full load truncates the existing target tables and reloads the data. This isn't possible for data pipelines using SCD2. If SCD2 target data is incomplete or corrupted, you should manually delete the tables from the target before re-running the data pipeline.
Refer to Stop a data pipeline for more information.