


Extract text from a PDF file
This example pipeline demonstrates how to extract text from a PDF file that contains table data.
-
Configure the Extract Snap—select the
Text and Full table checkboxes to extract text from the tables in the PDF
file.
On validation, the text is extracted. You can view the extracted text from the tables in the output preview.
Extract Snap configuration Extract Snap output 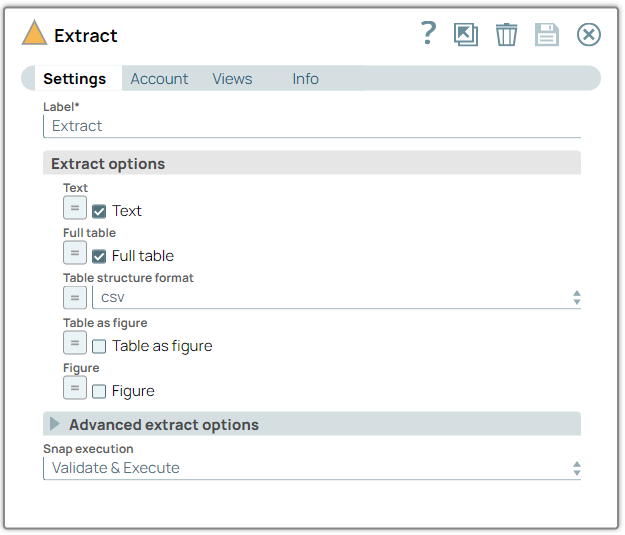

- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.