


Partition unstructured document
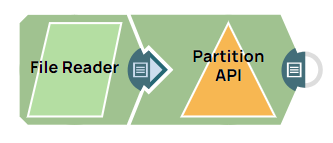
This example pipeline demonstrates how to extract structured content from a raw unstructured document using the Partition API.
-
Configure the Partition API Snap to
segment and process the extracted data from the unstructured document. Set the
Strategy to auto to generate output
containing tables and text.
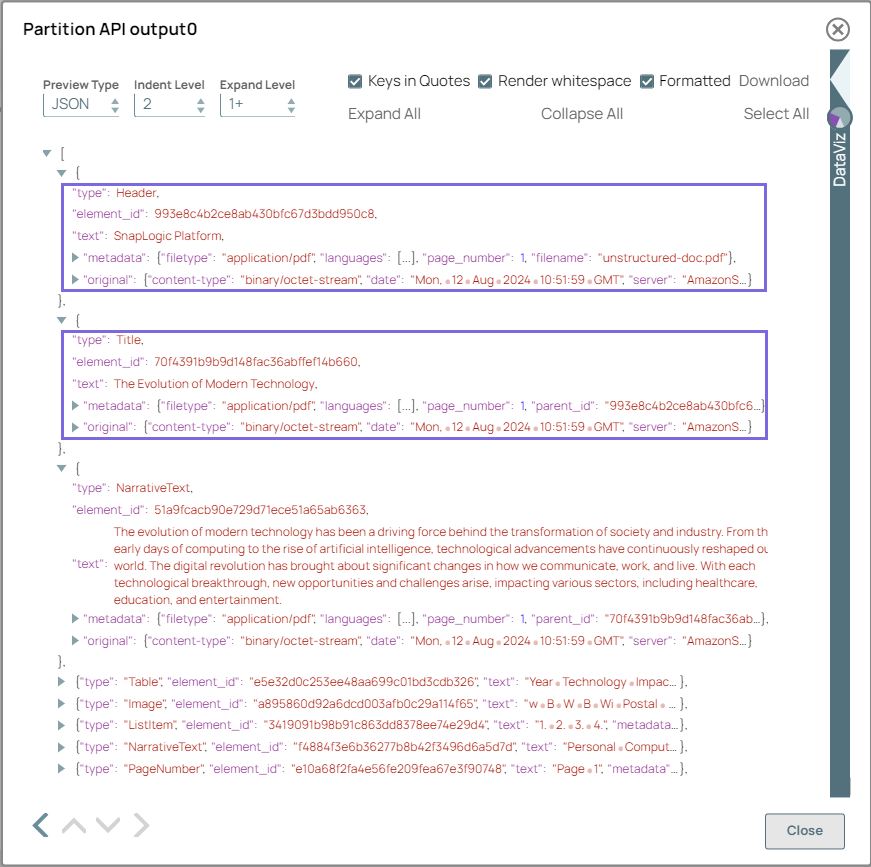
On validation, the Snap displays the partitioned output. The unstructured data is segmented into various structured components such as, Header, Title, NarrativeText, Table, Image, ListItem, and PageNumber.
Partition API Snap configuration Partition API Snap output 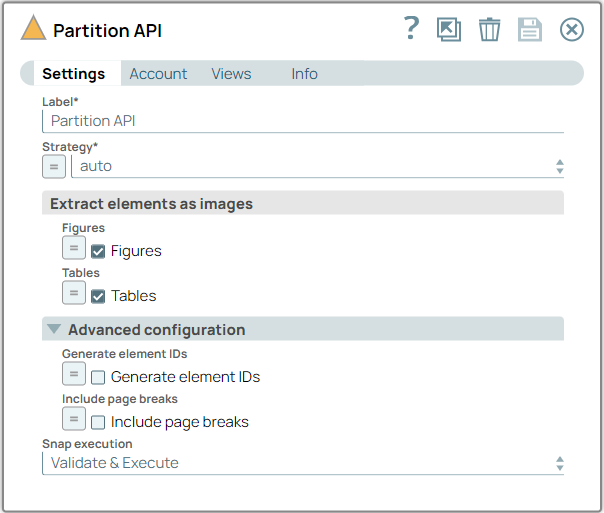
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.