


Target names and data types
Rules for table names and data types in the target.
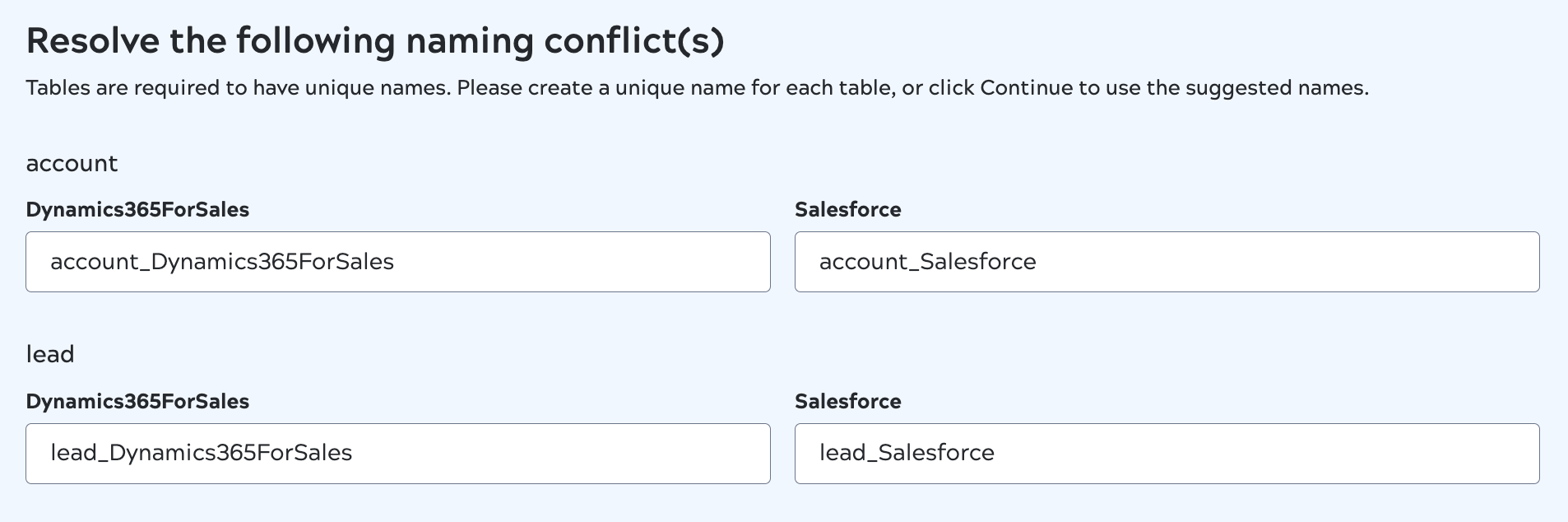
Table names must be unique in the target schema. If you select tables or objects with the same name from multiple sources for a data pipeline, AutoSync suggests unique names for the destination tables by appending the source type to the table name. You can accept the suggested names or enter your own.
- Uses the source table name, file name, or object name for the target table. If the table doesn't exist, AutoSync creates it.
- Converts the data into a compatible type supported by the destination. For JSON files, AutoSync can infer string, integer, float, boolean, and object types. For CSV files, by default AutoSync uses a string type in the destination. You can enable schema inference to have AutoSync infer basic types.
- Adds columns that AutoSync uses internally.
The column names are pre-pended with
AUTOSYNC_. Table names must be unique in the destination schema.
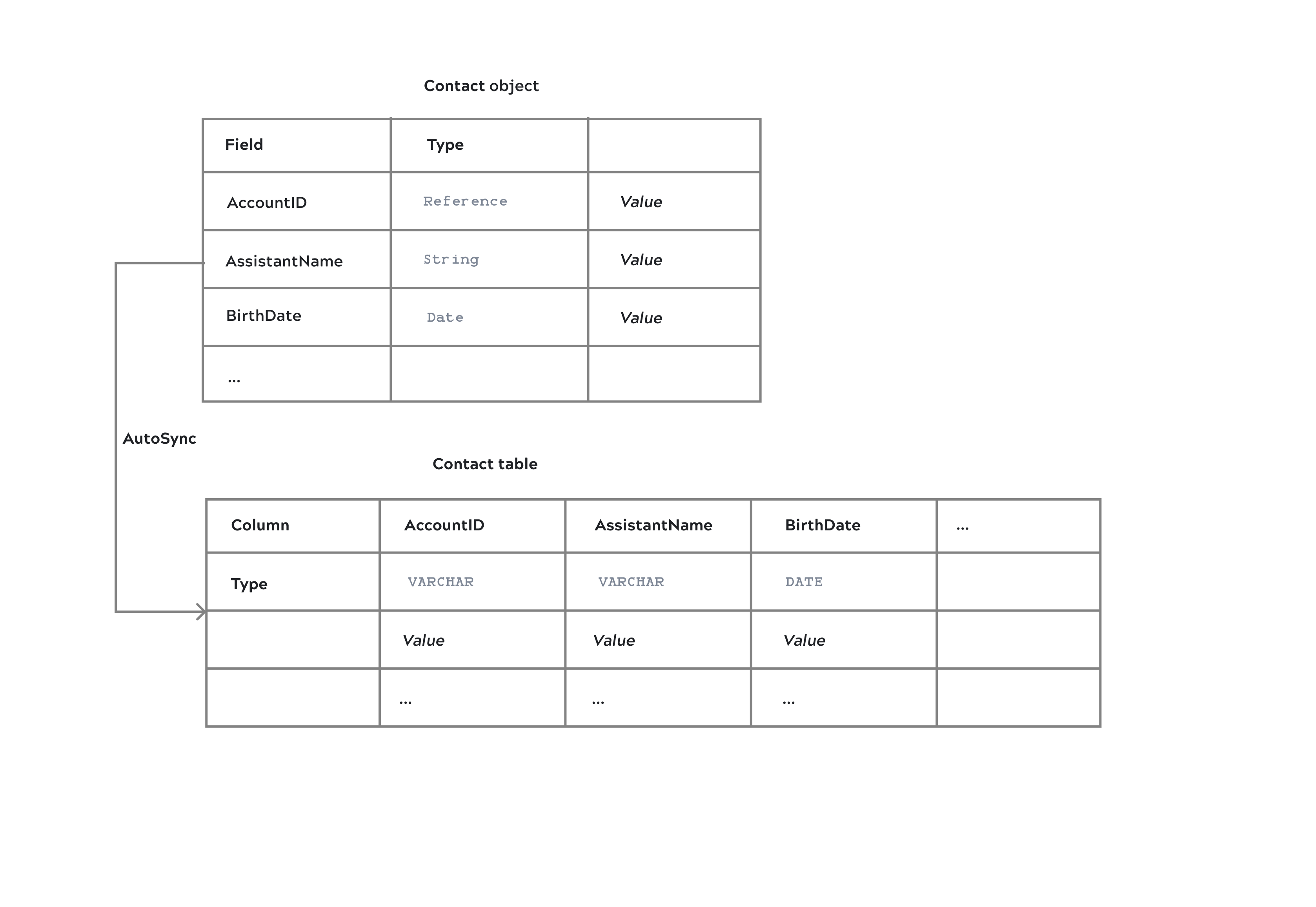
For example, the following image shows how AutoSync loads a Salesforce Contact object as a Contact table in Snowflake.
The image shows only the first three fields and columns in alphabetic order.
AutoSync converts the Salesforce Reference and String values to VARCHAR in Snowflake.
Because Snowflake supports the DATE type, AutoSync does not convert the birth dates.
Learn more about how AutoSync maps source data types to the target.
Naming conflicts
Reserved words and name casing
Destination endpoints typically have a set of reserved keywords that cannot be used as table or column names without using an escape character. Some destinations, such as Snowflake use a convention of uppercase letters for table and column names. By default, AutoSync will convert case to the convention of the destination and escape any reserved keywords. You might want to override this behavior if you have queries that are case sensitive and expect the case of the source.
When configuring a Snowflake endpoint, you can select the option to Enclose all target table and column names in double quotes to preserve the case.
The following table uses a reserved keyword, CONSTRAINT, to illustrate the results in the destination and the impact on the SQL query.
| Case preserved | Name in source | Name in target | SQL query |
|---|---|---|---|
| No | Constraint |
"CONSTRAINT" |
SELECT * FROM “CONSTRAINT” |
| Yes | Constraint |
"Constraint" |
SELECT * FROM “Constraint” |