


Identify the common words in a data set
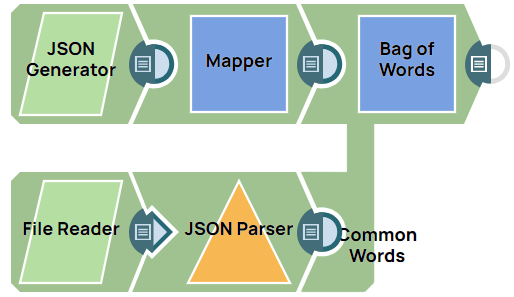
This example pipeline demonstrates how to calculate the frequency of common words appearing in a data set of tokenized sentences.
-
Configure the JSON
Generator Snap to pass your input data.
The input data contains an array of tokens created using the Yelp data set. Learn more on how to create similar arrays.Note: In this example, we use the JSON Generator Snap. However, you can replace the JSON Generator Snap with any Snap of your choice, such as the Chunker, Constant, File Reader , or S3 File Reader Snaps.

-
Configure the Mapper Snap as $text
to retain only the text from the input document.
On validation, the Snap displays the mapped data to be further used in the Bag of Words Snap.
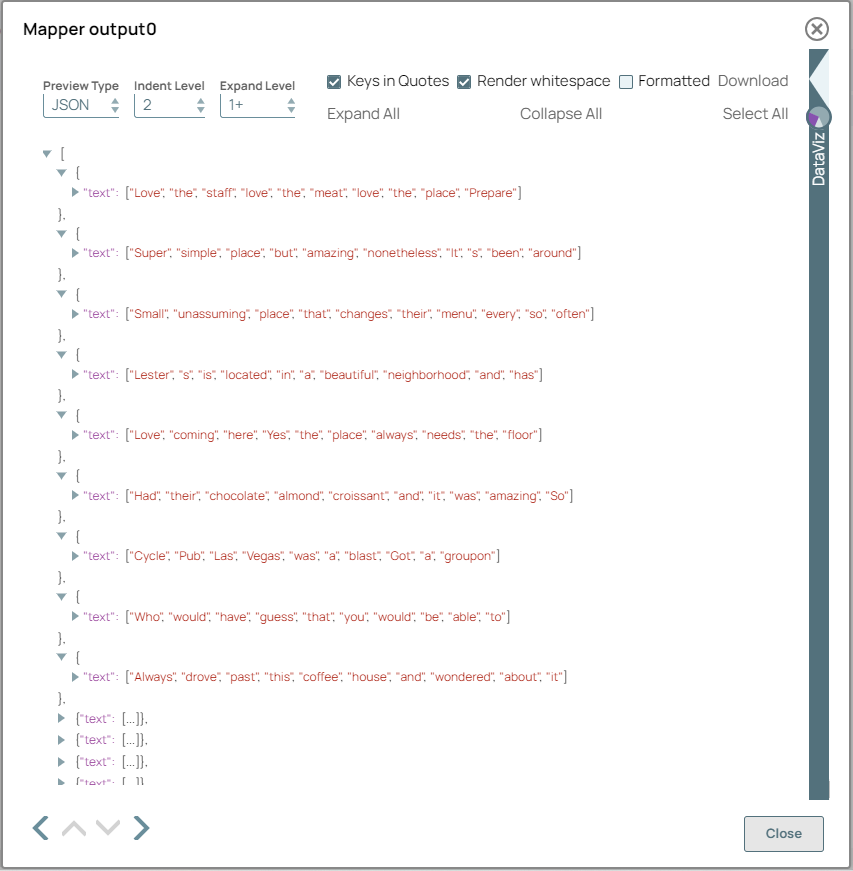
Mapper Snap configuration Mapper Snap output 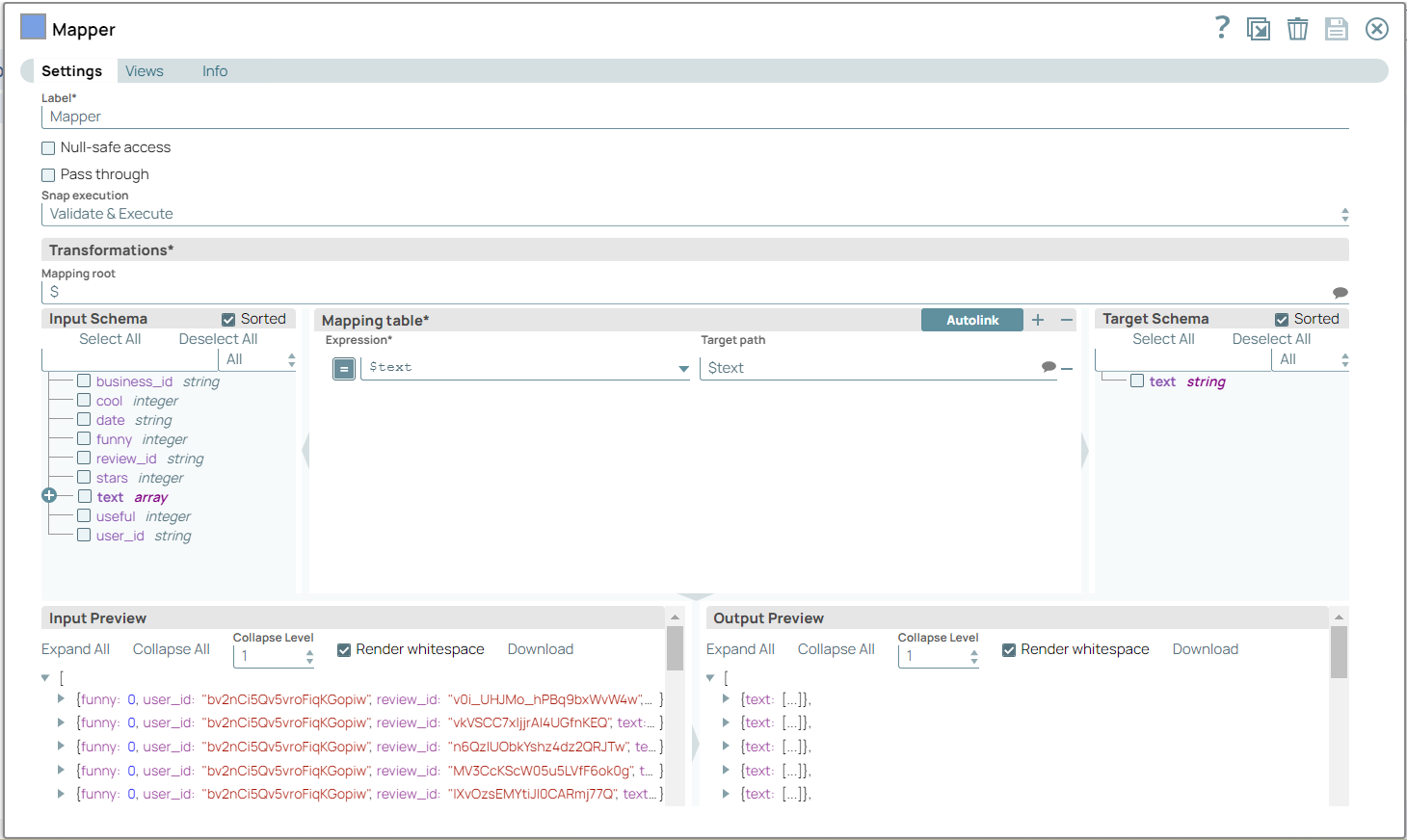
-
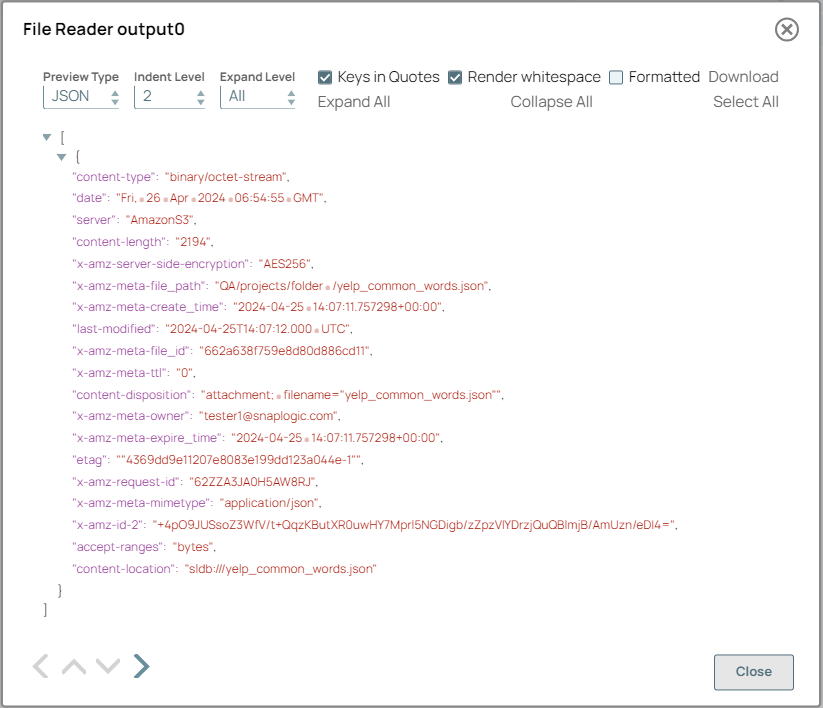
Configure the
File Reader
Snap to read the
contents of the yelp_common_words.json file, which contains the top
100 common words from the Yelp data set.
Learn more on how to create similar arrays with an example provided in the Tokenizer documentation. On validation, the Snap displays the read contents of the yelp_common_words.json file.
File Reader Snap configuration File Reader Snap output 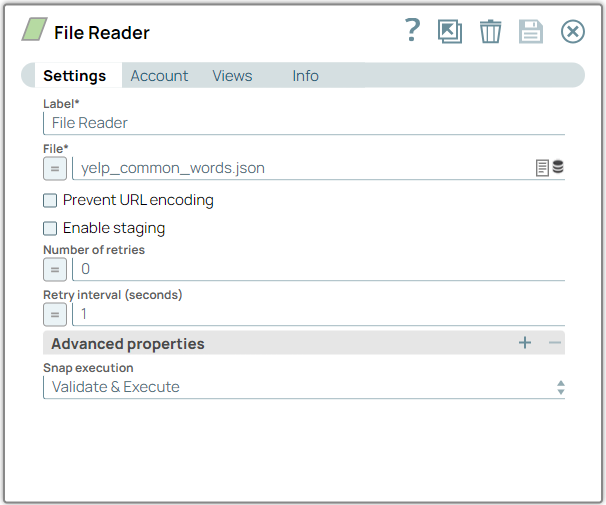
-
Configure the Bag of Words Snap with two input
views:
- Connect the first input view to the Mapper Snap to process the array of tokenized words in each sentence.
- Connect the second input view to the JSON Parser Snap to use the array list of the frequency of the 100 most common words for the same data set.
Bag of Words Snap configuration Bag of Words Snap output 
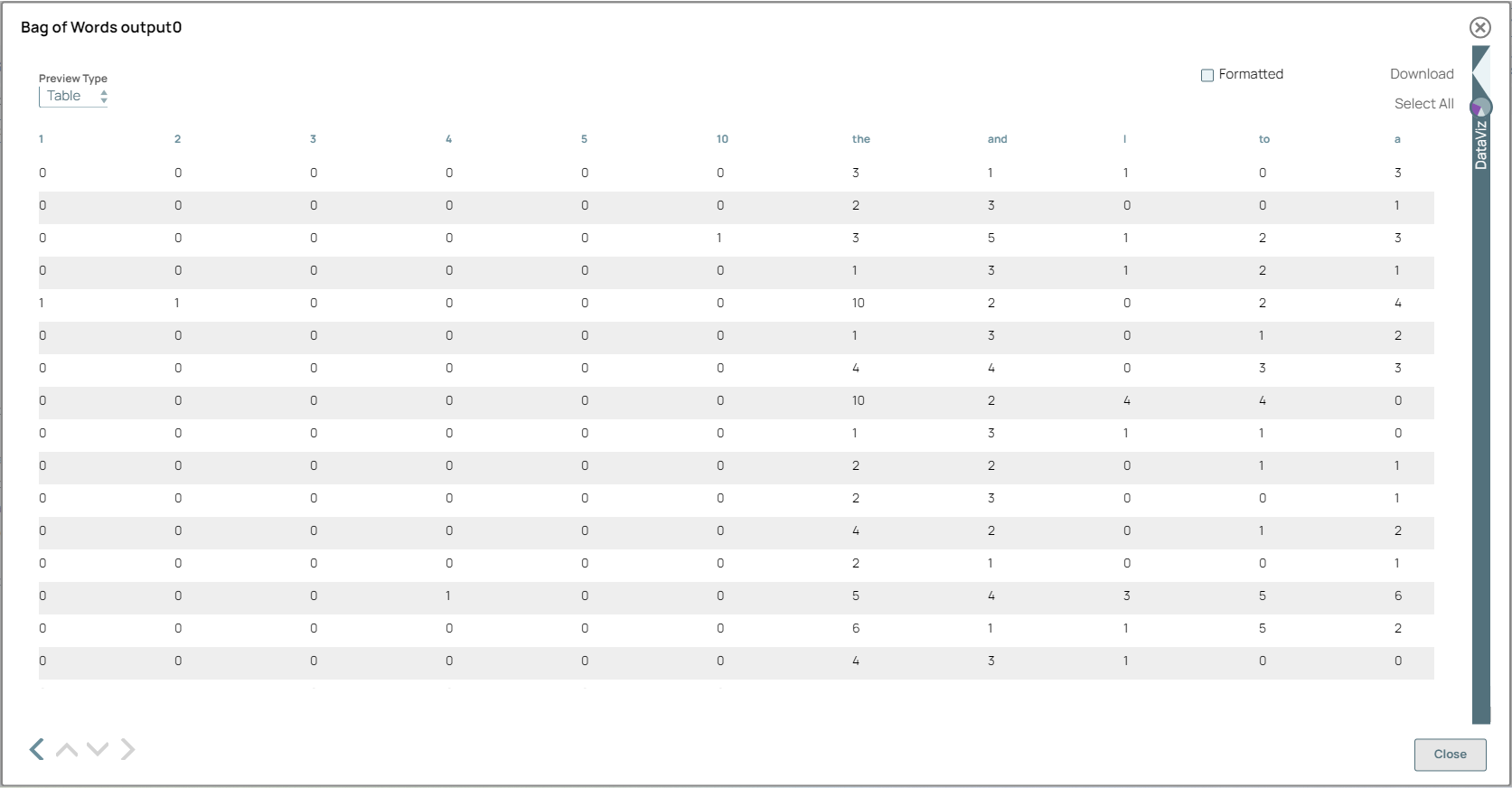
Note: After the data is generated, you can use Snaps such as the Filter and Aggregate Snaps for advanced processing. You can also use AgentCreator to integrate machine learning models.
- Download and import the pipeline into the SnapLogic Platform.
- Configure Snap accounts, as applicable.
- Provide pipeline parameters, as applicable.