


Heating load prediction – Cross validation
This pipeline demonstrates a typical cross validation exercise for a dataset before a model is trained to prediction the target field. The dataset is a record of various aspects of a building. The building's required heating load depends upon each of these aspects. The cross validation is to validate the model's ability to predict this heating load.

-
Configure the Cross Validator (Regression) Snap to perform K-fold Cross Validation.
The Cross Validator (Regression) Snap splits the dataset into training and test sets, which are used to evaluate the selected ML algorithm.
Cross Validator (Regression) Snap Configuration Cross Validator (Regression) Snap Output 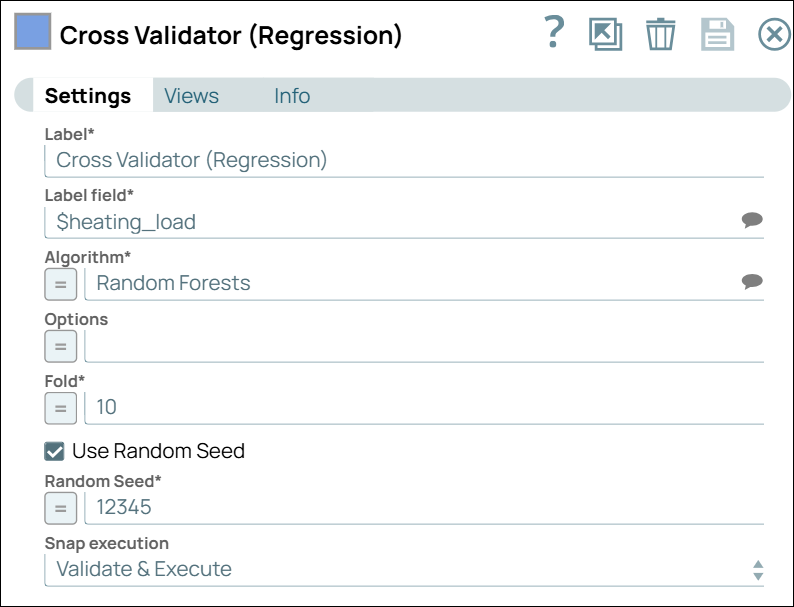
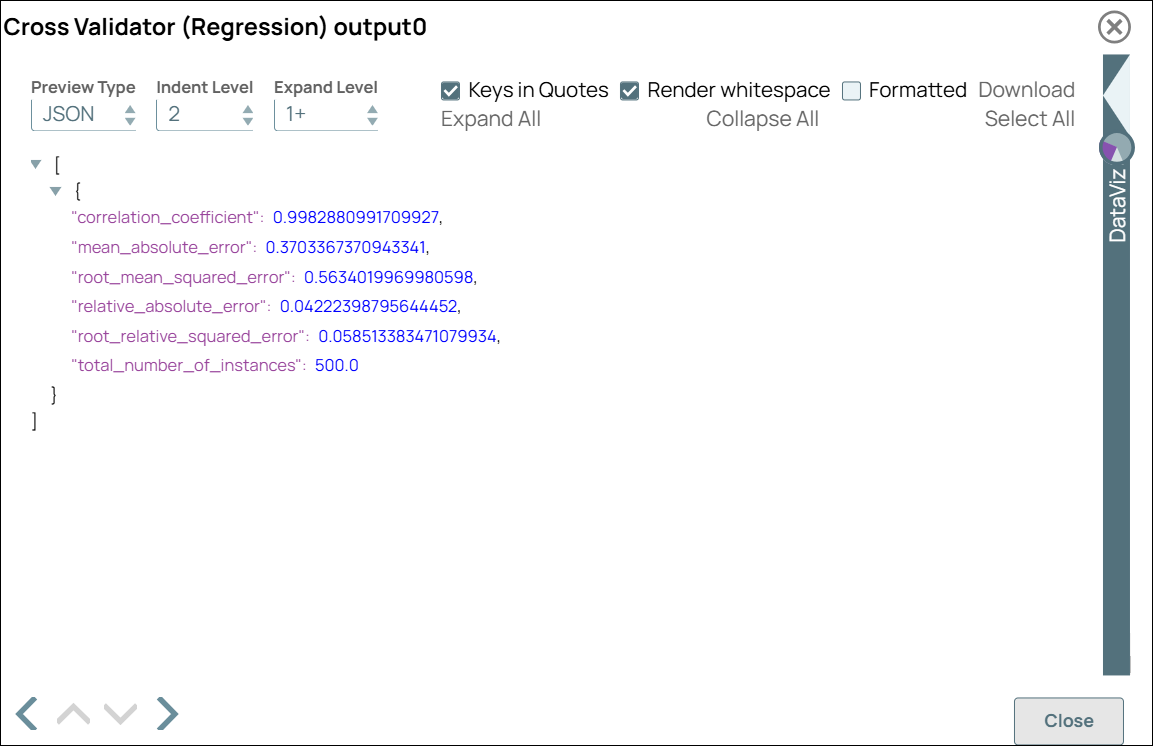
Note: You can optionally write the output to a file using the downstream File Writer Snap for storage or further analysis.
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.