


Request execution flow
A call to a SnapLogic Service goes from the client to a Snaplex node, ideally through a load balancer. The Snaplex node applies the inbound rules for all Policies associated with the endpoint. Inbound rules include validation, authentication, authorization, shape, and transform. For external endpoints, the node then applies outbound rules for authentication and forwards the request to the external server. Before returning the response to the client, the original node applies any rules defined for the response. Refer to Introduction to Policies for more details on request inbound, request outbound, and response rules.
For how the platform constructs the path that reaches the upstream (and the
PATH_INFO value the backing pipeline receives), refer to
Path resolution.
The execution flow and application of rules differs between native (tasks) and external endpoints:
- For native endpoints, the Snaplex applies any associated inbound rules locally without additional
network calls.
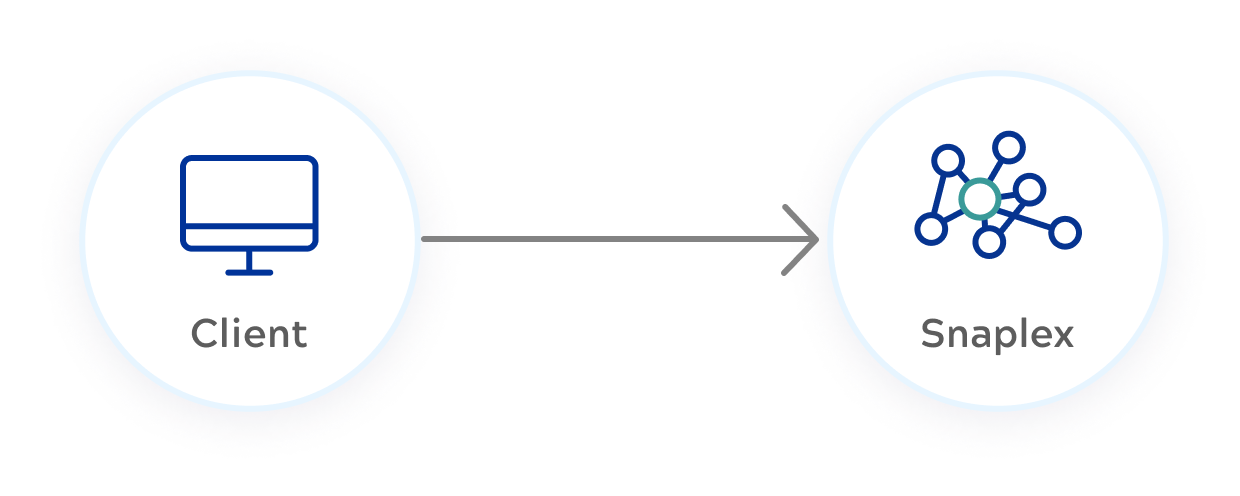
- External endpoint requests go first to the Snaplex, which applies inbound
rules, applies outbound rules, and forwards the request to the external URL. For example, as shown
in the following diagram, the third-party API is a Salesforce API. The outbound rules enable
Salesforce to authenticate the request.

Alternative request paths
Some use cases might require a Triggered or Ultra Task to execute on a different Snaplex than the one that receives the request. To accomplish this, create a second Service with an endpoint that executes on the second Snaplex. Add an external endpoint to the first Service that calls the second Service endpoint. You need to add authentication rules to deal with the outbound request. The following image illustrates this flow:
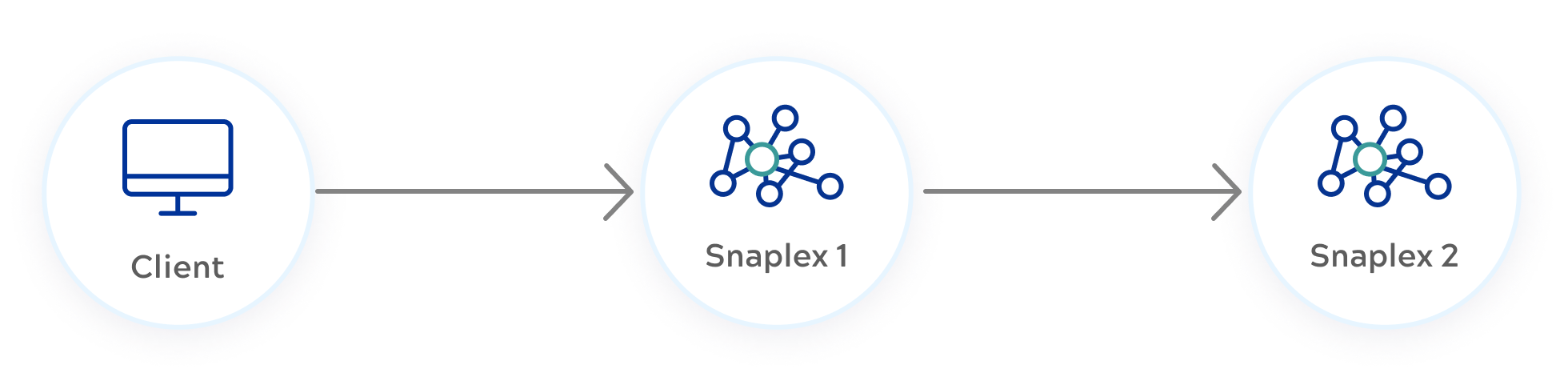
You might choose execution on another Snaplex for a number of reasons, but be aware that this requires an additional network call and the two Snaplexes must be able to communicate with each other. For this pattern, we recommend using the endpoint URL from another Service because that applies Policies. You can use a Cloud URL from a task, but that isn't handled by APIM 3.0 and no Policy rules will be applied.
Authorization and authentication
Authentication verifies the identity of the caller and authorization
determines which resources they have permission to access. You need to configure both types of rules.
Unless basic authentication applies, a request that doesn't satisfy authentication returns a
401 error code. If no authorization rule is defined or the requestor isn't
authorized, the request returns a 403 error code.
APIM 3.0 offers the Authorize by role rule to handle authorization and rules that support the following authentication methods:
- Anonymous
- API key
- Outbound Basic Auth rule (with a SnapLogic user name and password)
- Generic OAuth2 rule
- OAuth 2.0 Client Credentials rule
- JWT Validator rule
Caching
The Response Cache rule in APIM 3.0 supports caching. You can configure it to apply to all Services or specific Services and endpoints. For example, to apply at the endpoint level, you might start with GET methods. Combined with the Request Size Limit and Client Throttling rules, this can help improve performance by reducing latency, bandwidth consumption, and backend load.
Cache key is useful with services running on a server with low capacity, low memory, and only used for one job. If requests come in, but if the API response is cached, you can save upstream executions by retrieving the payload stored in cache when requested.
Retry logic
The HTTP Retry rule applies to external endpoints and enables client-side retry logic. This rule causes the Snaplex to take a snapshot of the header and payload. Until a response or the retry limit is reached, the Snaplex continues to retry the request.
The SnapLogic Platform offers retry logic for some Snaps. For example, the Pipeline Execute Snap orchestrates the calling of child pipelines and features a retry setting. Ultra Tasks also offer retries for pipelines with a request-response design.