


Use multiple sources in one data pipeline
When creating a data pipeline in the wizard, you can select up to five source endpoints. Multi-source data pipelines have the following features and limitations:
- The CSV file endpoint can't be used with other sources.
- Names in the target must be unique. If you select a table with the same name from multiple sources, AutoSync suggests unique names for the target. You can also specify your own.
- AutoSync uses the default load type common to all sources in the data pipeline. For example, if one source only supports Full load and all other sources support Incremental, AutoSync uses Full load.
- After you save a data pipeline with multiple sources, you can't change the sources or destination. You can edit it to select different tables, change the load type, change the schedule, or change transformations.
Resolve naming conflicts
If you select tables with the same name from multiple sources in the wizard or edit screens, AutoSync will prompt you to rename them:
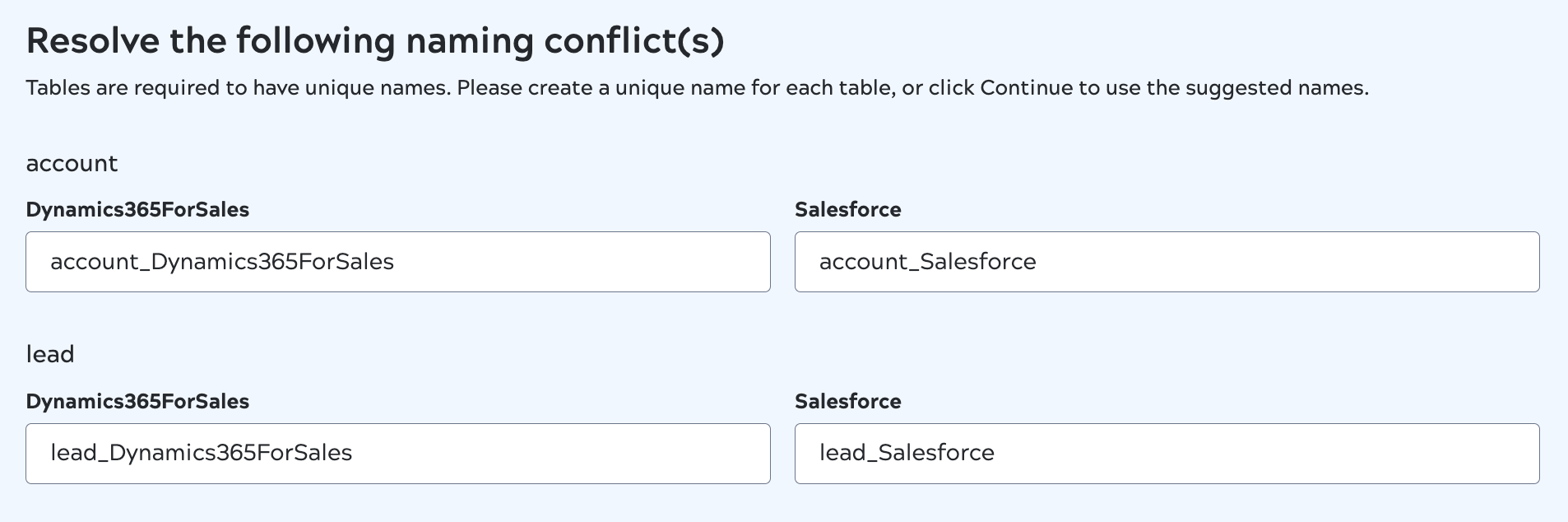
AutoSync suggests new table names based on the associated endpoint. If you prefer a different name, enter it in the text field and click Save when finished.