Transform data using a select query
The following example pipeline demonstrates how you can reorder the columns using the SELECT statement transform option before loading data into Snowflake database. We use the Snowflake - Bulk Load Snap to accomplish this task.
Prerequisite: You must create an internal or external stage in Snowflake before you transform your data. This stage is used for loading data from source files into the tables of Snowflake database.
To begin with, we create a stage using a query in the following format. Snowflake supports both internal (Snowflake) and external (Microsoft Azure and AWS S3) stages for this transformation.
"CREATE STAGE IF NOT EXISTS "+_stageName+" url='"+_s3Location+"' CREDENTIALS =
(AWS_KEY_ID='string' AWS_SECRET_KEY='string') "This query creates an external stage in Snowflake pointing to S3 location with AWS credentials (Key ID and Secrete Key).
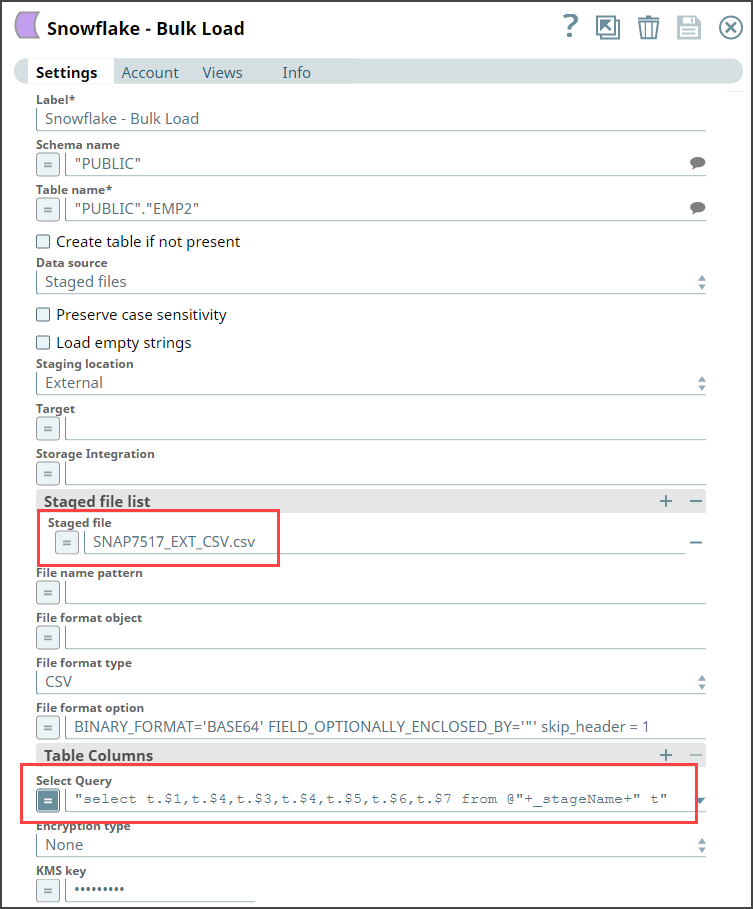
Now, add the Snowflake - Bulk Load Snap to the canvas and configure it to transform
the data in the staged file SNAP7517_EXT_CSV.csv by providing the following query in
the Select Query field: "select t.$1,t.$4,t.$3,t.$4,t.$5,t.$6,t.$7
from @"+_stageName+" t"
- SELECT t.$1,t.$4,t.$3,t.$4,t.$5,t.$6,t.$7 from @mys3stage t", displays an error.
- SELECT t.$1,t.$4,t.$3,t.$4,t.$5,t.$6,t.$7 from @<Schema Name>.<stagename> t", executes correctly.