


Athena Create Table
Overview
You can use this Snap to create Iceberg/Athena table from existing S3 Parquet files. The Snap can read the schema in the source file and convert it to the Athena/Iceberg table schema. It also can get the table schema from the second input view. It first creates a temporary table from the source files and then creates the target table in the target directory using CTAS (CREATE TABLE AS SELECT) statement so that the source data can be re-arranged according to the Partitioned by columns in the target files.
- This is a Write-type Snap.
 Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
None.
Known issues
- Choosing the Overwrite option for the If table exists or S3 directory is not empty field deletes the existing Athena table and its associated S3 objects when the Snap execution starts. Use this option cautiously to prevent data loss.
- The TIMESTAMP data type is not supported when using the ICEBERG
table type in the Athena Create Table Snap.
Workaround: Use the STRING data type for timestamp values instead.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has two document input views. You can use the second input view to
specify the column metadata of the Athena table. Important:
|
|
| Output | This Snap has one document output view. | |
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value.
): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
Label
|
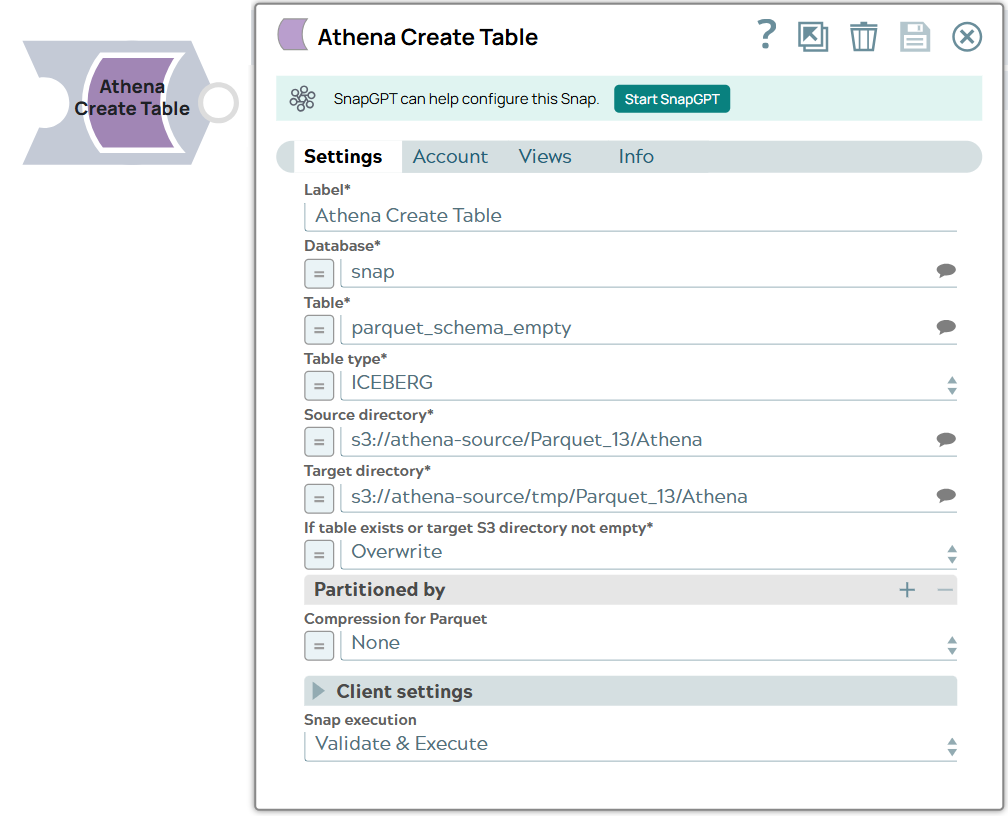
String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Athena Create Table Example: Athena Create Table - Students |
| Database | String/Expression/ Suggestion | Required. Specify the name of the Athena database, that is a logical grouping of Athena tables. Default value: N/A Example: yourdatabase |
| Table | String/Expression/ Suggestion | Required. Specify the name of the Athena table for the Snap to create. Default value: N/A Example: Sales_db |
| Table type | Dropdown list/Expression | Required. Choose the type of table to be created.
Available options are:
Default value: ICEBERG Example: ATHENA |
| Source directory | String/Expression/ Suggestion | Required. Specify the Amazon S3 directory It must end with '/' and contain the Parquet files with the same column metadata. The Snap reads all Parquet files in the source directory to create the target table, and Athena CTAS statement rewrites the Parquet data into the target directory. Default value: s3://<bucket>/<path>/ Example: s3://test-bucket/parquet/source/ |
| Target directory | String/Expression/ Suggestion | Required. Specify the Amazon S3 directory path where the resulting Parquet data is stored. Default value: s3://<bucket>/<path>/ Example: s3://test-bucket/parquet/target/ |
| If table exists or target S3 directory is not empty | Dropdown list/Expression | Required. Choose the action to perform if the target
table name already exists or the specified S3 directory is not empty. Available
options are:
Default value: Error Example: Overwrite |
| Partitioned by | Use this field set to define the table partitioning according to the column values. | |
| Column | String/Expression/ Suggestion | Specify the list of column names to write input data into multiple S3 objects. Important:
Default value: N/A Example: partnername |
| Compression for Parquet | Dropdown list/Expression | Appears when Parquet is selected in the Data format field and ATHENA in the Table type field. Choose the compression type for Parquet files. Available options are:
Default value: None Example: SNAPPY |
| Client settings | Use this field set to define the client settings. | |
| Maximum retries | Integer/Expression | Required. Specify the maximum number of retry attempts.
Default value: 3 Example: 10 |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Example: Validate & Execute |