


Use Case: Synchronize tables in another database
Overview
This use case demonstrates how to synchronize tables between two databases, ensuring that data remains consistent and up-to-date across systems. It covers the process of extracting data from a source database, transforming it, and loading it into a target database. This pipeline is ideal for scenarios such as data replication, migration, or maintaining backup systems, and supports real-time or scheduled synchronization based on business requirements.
Problem
The HR system application lacks a built-in feature for automatically synchronizing data with external applications or databases. Additionally, it lacks an interface to support this synchronization process. This limitation poses challenges in maintaining consistent data between the HR system and other systems, necessitating manual intervention or the development of custom solutions.
Solution
This pipeline captures and retrieves the data changes (Insert, Update, and Delete statements) performed on the Customer table. These changes are written to the target tables in the SQL Server database, ensuring data consistency.

Understanding the Solution
- Extract data from the Oracle database
- Transform data before loading
- Load data into SQL Server database
-
Configure the Oracle CDC Snap to extract transactional changes (Insert, Update, Delete) from the source table in the
HR system.
The Snap is configured to perform CDC on the
CUSTOMERtable within theCDCUSERschema to extract Insert, Update, and, Delete operations, for the time period from December 1, 2024, 00:00:01 to December 31, 2024, 00:00:01.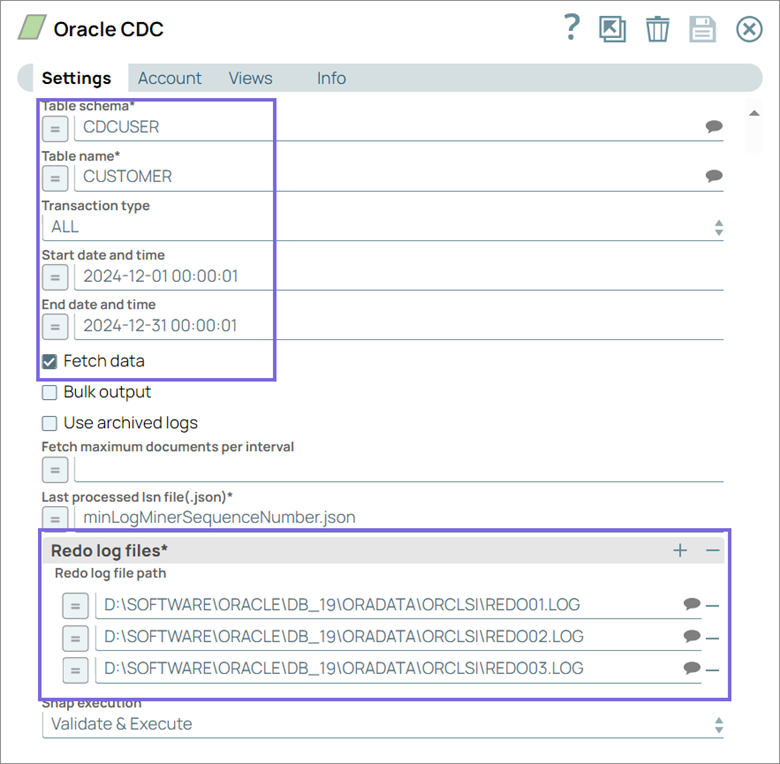
-
Configure the
Router
Snap to route the extracted
documents based on the operation.
-
Add three output views to route the data into three routes:
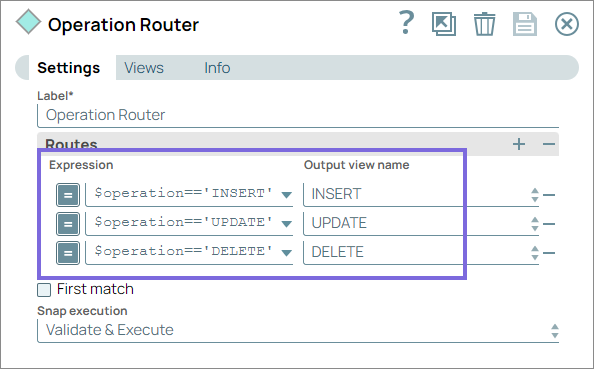
- Insert: Handles documents representing Insert operations.
- Update: Processes documents corresponding to Update operations.
- Delete: Manages documents associated with Delete operations.
This routing ensures that each type of operation is processed separately, enabling precise handling and mapping for each action.
-
Connect three Mapper Snaps to all the
routes to map the data with the target database table's structure and
requirements.
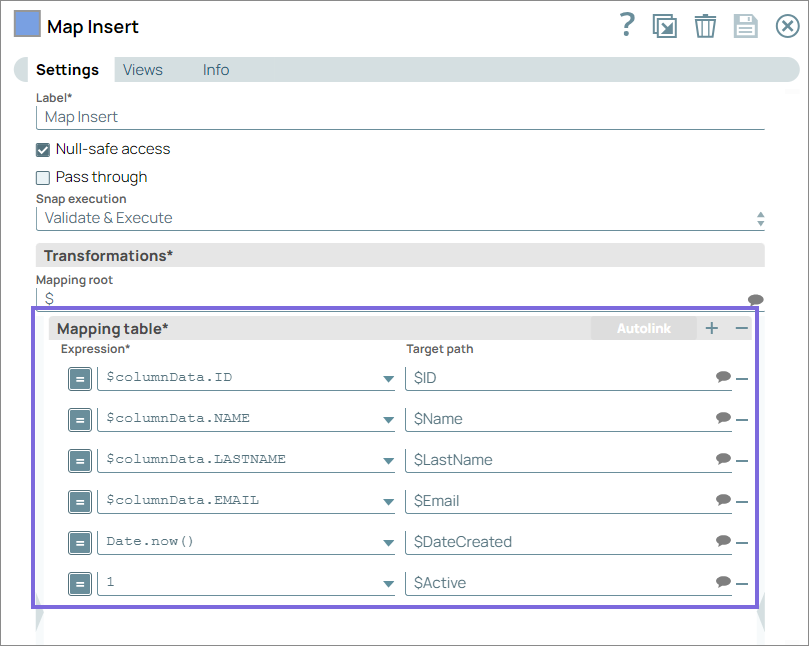
- Map the customer records to the target Customer table as shown below:
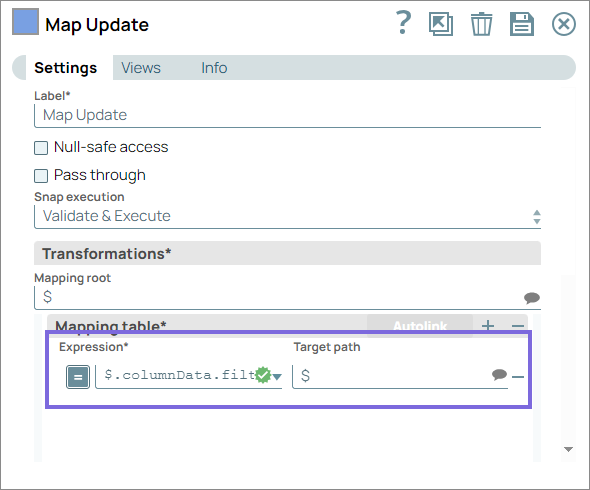
- Update existing customer records in the target table.
- Mark customers as inactive in the target table if the corresponding record is
deleted in the source table.
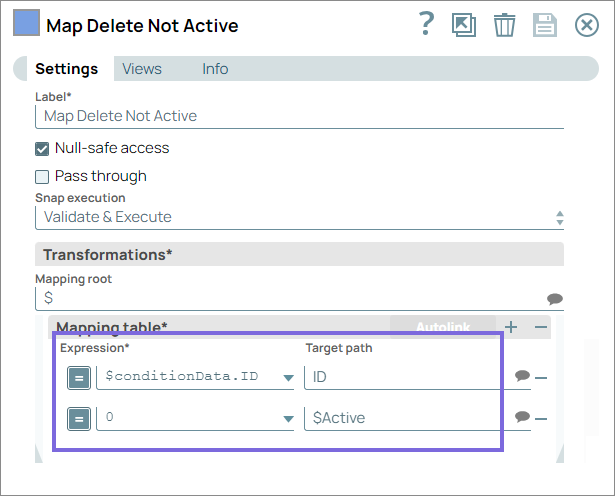
- Map the customer records to the target Customer table as shown below:
-
Add three output views to route the data into three routes:
-
Connect SQL Server (Insert and Update) Snaps downstream of each of the Mapper Snap to synchronize the data.
-
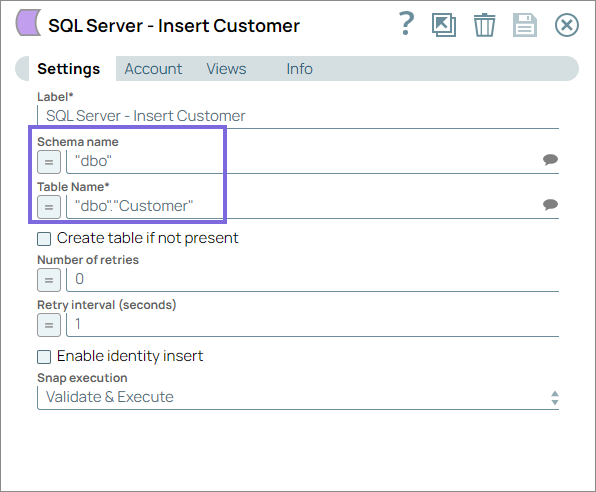
Configure the SQL Server - Insert Snap to insert
new customer records into the target Customer table. This configuration ensures that
all new customer records are properly structured and enriched with additional metadata
during the Insert operation.
-
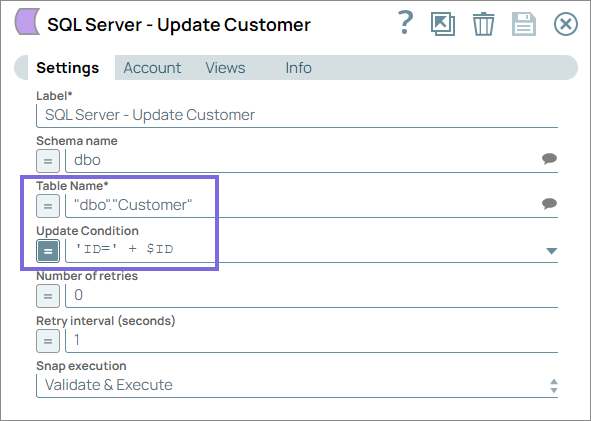
Configure the SQL Server - Update Snap to update
existing customer records in the target table using the ID as Update Condition.
-
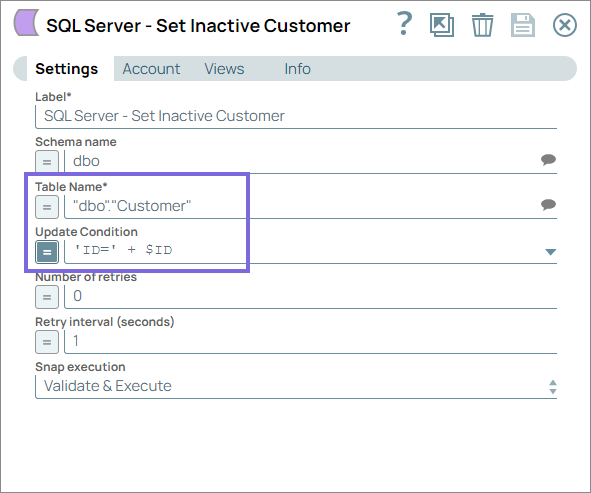
Configure the SQL Server - Update Snap to flag the
inactive customer records using the Update condition. This configuration ensures that
deleted records are not permanently removed but are instead flagged as inactive,
preserving data integrity while reflecting the deletion status.
-
Configure the SQL Server - Insert Snap to insert
new customer records into the target Customer table. This configuration ensures that
all new customer records are properly structured and enriched with additional metadata
during the Insert operation.
- Download and import the pipeline into SnapLogic.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.