


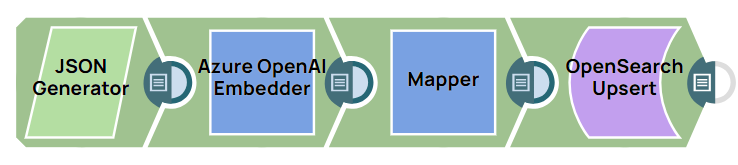
Insert and update documents in OpenSearch
This example pipeline demonstrates how to insert and update records in the OpenSearch database.
-
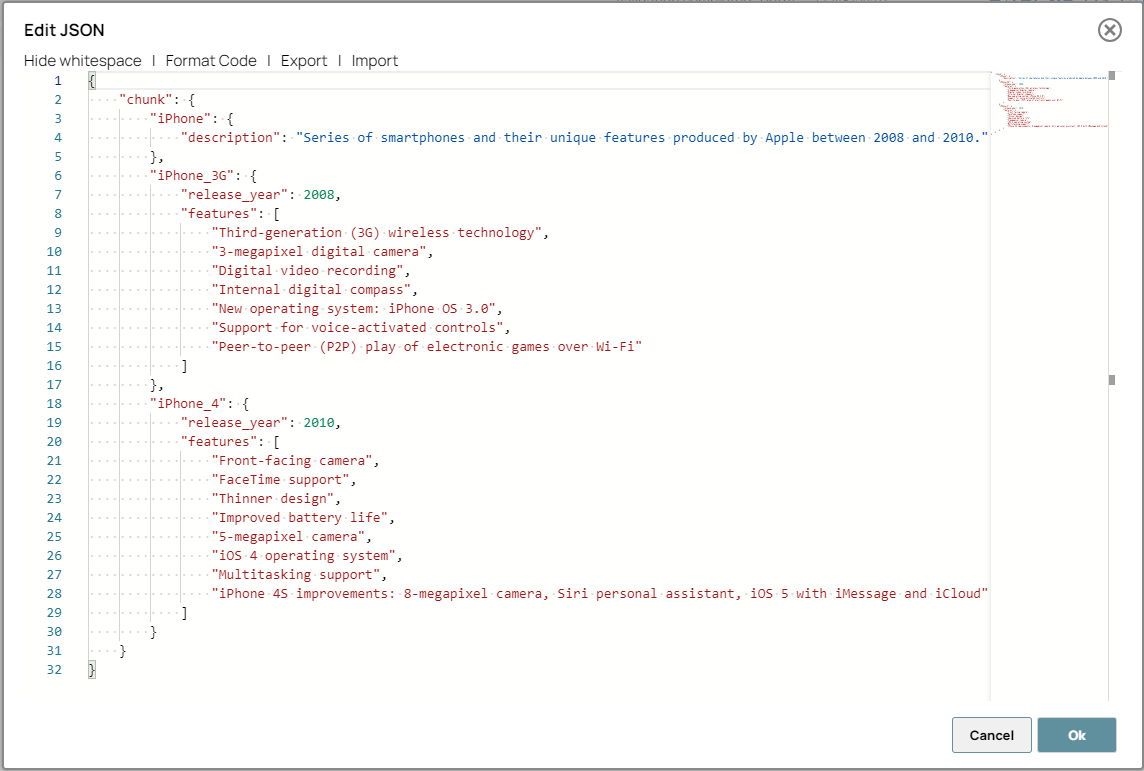
Configure the JSON
Generator Snap with the
required content in the chunk to be passed in the Azure OpenAI
Embedder Snap for generating embedding vectors.
Note: In this example, we use the JSON Generator Snap. However, you can replace the JSON Generator Snap with any Snap of your choice, such as the Chunker, Constant, File Reader , or S3 File Reader Snaps.
-
Configure the Azure OpenAI Embedder Snap to generate
embedding vectors for input data based on the Deployment ID, Batch size, and input
document.
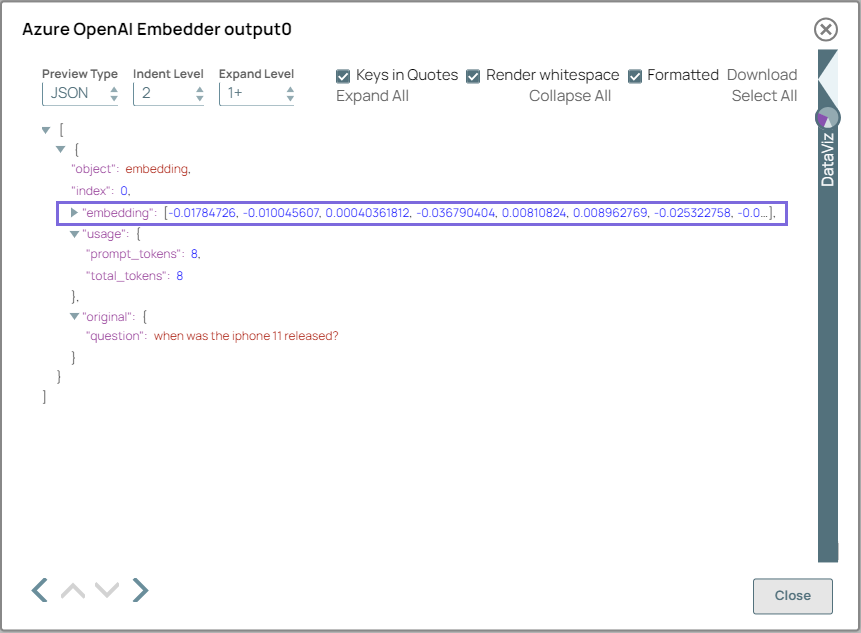
On validation, the input data from the upstream Snap is processed into embedded vectors and you can view the embeddings as vector data in the output preview.
Azure OpenAI Embedder Snap configuration Azure OpenAI Embedder Snap output 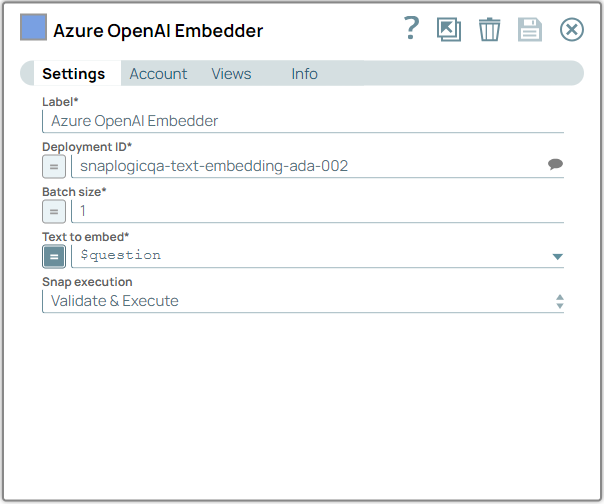
-
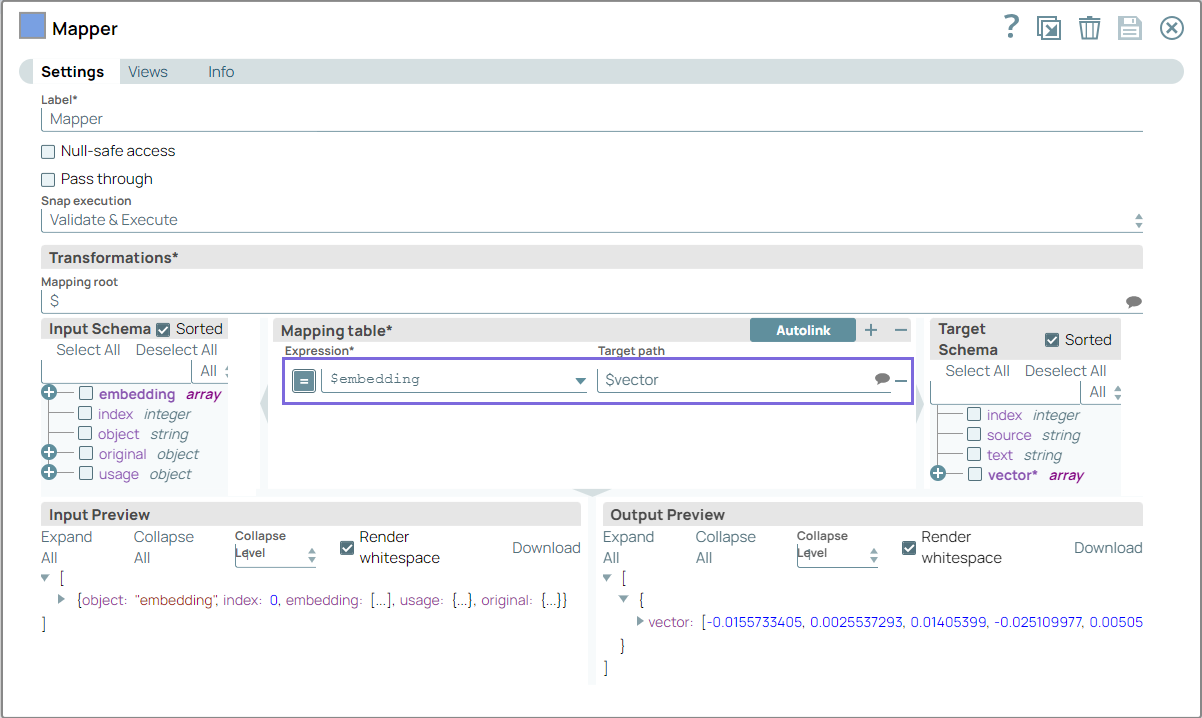
Configure the Mapper Snap with the
generated embeddings with $vector, ensuring the embeddings are
correctly mapped to the appropriate fields for the subsequent query.
-
Configure the OpenSearch Upsert Snap with the
Index name and Batch size to insert
documents in the specified index.
Note: The OpenSearch Upsert Snap updates records of the associated object if the record ID exists; otherwise, it creates a new record.
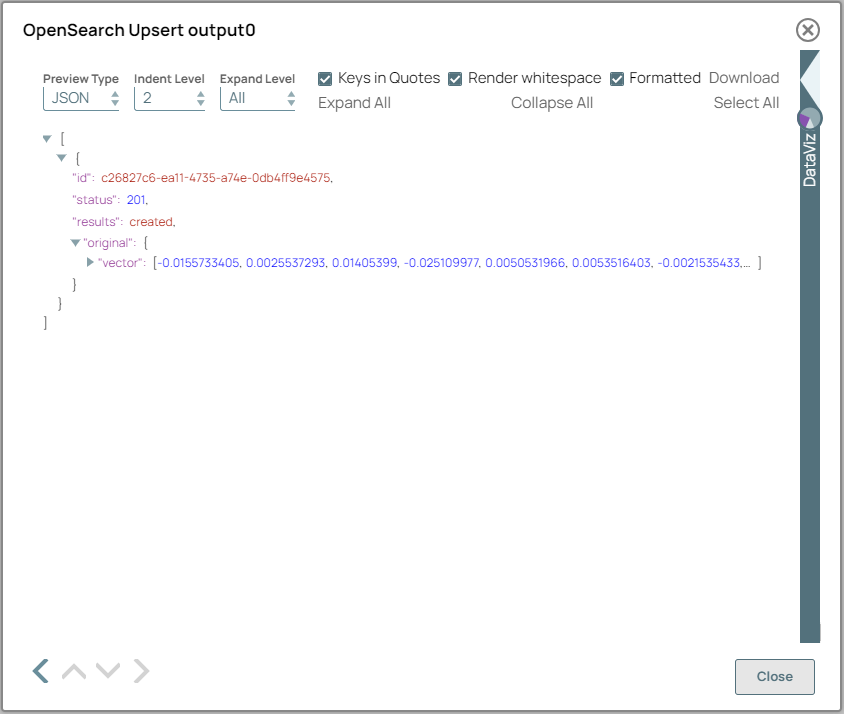
On validation, the Snap displays a success message for the upserted document, including the ID that is generated for this document.
OpenSearch Upsert Snap configuration OpenSearch Upsert Snap output 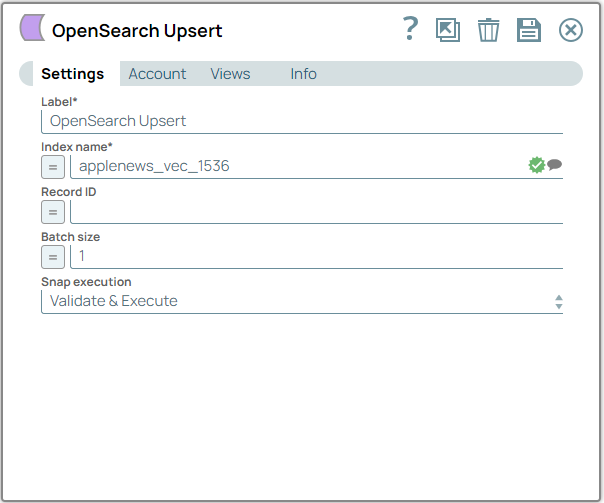
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.