


How AutoSync loads data
SnapLogic AutoSync retrieves data from the sources you choose and loads it to the target. Source data can come from CDWs, relational databases, files such as CSV and JSON, or applications such as Salesforce, Zendesk, and Gainsight. To optimize throughput, AutoSync loads in batches when possible. View the list of all supported endpoints.
When you schedule a data pipeline, AutoSync synchronizes the data from the source to the target automatically. Depending on the sources and target in the data pipeline, synchronization might result in a full load where existing target tables are dropped and then reloaded, an incremental load, an append (for CSV files only), or an SCD2 load, which captures historical changes. You can change the synchronization schedule or load type after creating a data pipeline.
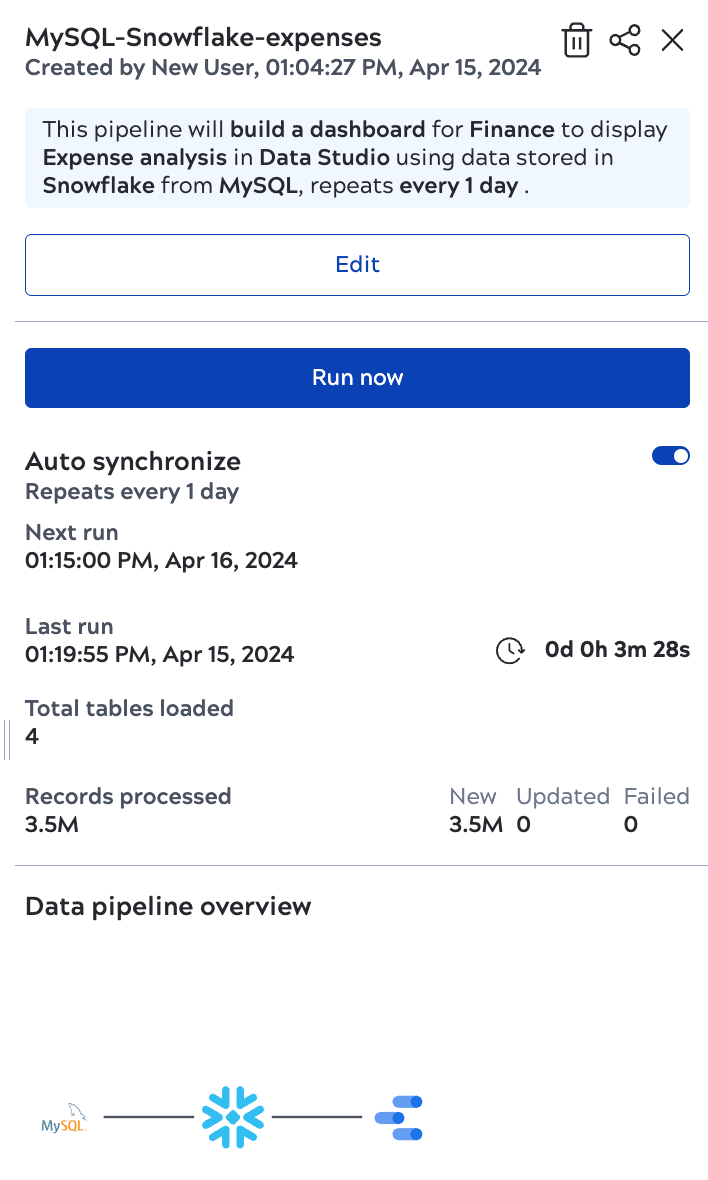
To verify the number of records that AutoSync processed, check the data pipeline details panel. Open the panel by clicking the data pipeline card. As shown in the screenshot below, the details panel lists the number of new or updated records and those that failed to load.
Refer to How AutoSync loads files for information on file loading. The following describe how AutoSync loads data to a target from relational and application sources: