


Group By N
Overview
The Snap groups data from multiple input documents into each output document. Each output document contains an array of input data at the location specified by the Target field property. The size of an array is specified by the Group size property. The number of output documents is, the number of input documents divided by the Group size, rounded up, except when the Memory Sensitivity property is set to Dynamic, which allows the group size to vary dynamically.
- This is a Transform-type Snap.
 Does not support Ultra Tasks
Does not support Ultra Tasks
Prerequisites
All input documents should be of Map data type.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has exactly one document input view. A document with a Map data. |
|
| Output | This Snap has exactly one document output view. A document with a list of input data as a value at the location specified by the Target field. |
|
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value.
): Allows using
pipeline parameters to set field values dynamically (if enabled). SnapLogic Expressions
are not supported. If disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
Label
|
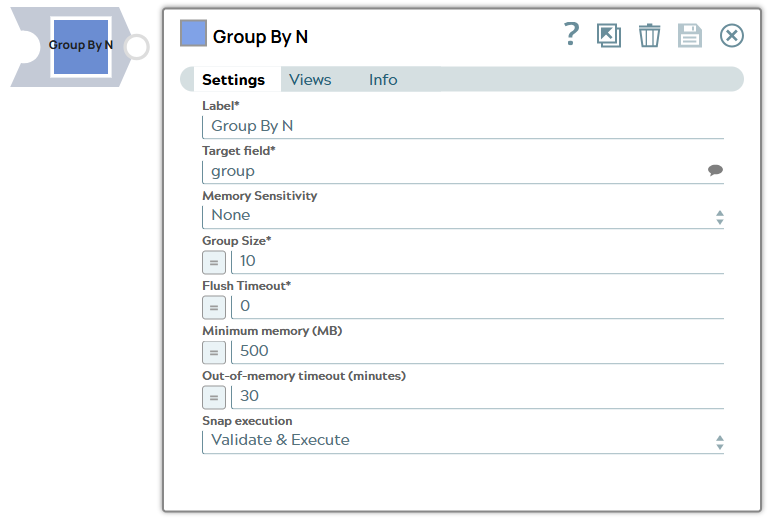
String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Group By N Example: Group By N |
| Target field | String/Suggestion |
Required. Specifies the JSON path where the group array should be located within each output document. Default value: "group" Example: "grouped_data", "$group", "$group.list" |
| Memory Sensitivity | Dropdown list | Indicates the Snap's behavior towards memory changes. Choose one of the available options:
Default value: None Example: Dynamic |
| Group size | Integer/Expression | Required. Enter the number of input documents to be
grouped into a single output document. A value of 0 instructs the Snap to group
all the input documents into a single document. When Memory Sensitivity is
Dynamic, this field specifies the maximum size of the group.
Note: When the input stream ends, the Snap outputs the final group,
regardless of the Group Size. For example, if the input stream has 105 documents
in it, and the Group Size is 100, the Snap outputs one group of 100 and one group
of 5. Important: This is an expression-enabled property;
however, you can only pass data for this property using Pipeline parameters or
expressions. This Snap does not support passing upstream data. Default value: 10 Example: 15000 |
| Min Group Size | Integer/Expression | Appears when Memory Sensitivity is set to Dynamic. Enter the minimum number of input documents to be grouped into a single output document. Note: We recommend setting this value to 5% or less of the Group Size. It should
not be higher than 10% of the Group Size. This setting is not applicable to the
last group and flushed groups.
Default value: 1 Example: 2 |
| Flush Timeout | Integer/Expression | Required. Enter a non-zero value in this field to specify the number of seconds which can pass with no new input before the Snap should output a partial group, a group containing fewer than Group Size input documents. Note:
When the Flush Timeout is 0, the Snap waits until it receives the messages specified in the Group Size field. The Flush Timeout is useful in scenarios where the input stream never ends, or has long pauses as documents are read from it. In scenarios, where the Snap continually polls from an external system for new data, such as Kafka Consumer or Salesforce Subscriber Snaps, you can use the Flush Timeout field to specify a timeout so that the Snap always outputs whatever is available. For example, if the Group Size is 100 and 105 records are currently available from Kafka application, the Snap passes output in two groups (100 and then 5), and continues to wait for more records. If the upstream Snap outputs another 15 records that are available, another group of 15 or more is passed, after the Flush Timeout is reached. Default value: 0 Example: 10 |
| Minimum memory (MB) | Integer/Expression |
If the available memory is less than this property value while processing input documents, the Snap stops to fetch the next input document until more memory is available. This feature is disabled if this property value is 0. Default value: 750 Example: 500 |
| Out-of-memory timeout (minutes) | Integer/Expression |
If the Snap pauses longer than this property value while waiting for more memory available, it throws an exception to prevent the system from running out of memory. Default value: 20 Example: 30 |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Example: Validate & Execute |