


Unloading data from a table in DLP to a CSV file
Consider the scenario where we want to unload the employee data for an organization from a DLP table to a CSV file. Let us see how we can achieve this using the Databricks - Unload Snap.
- Here is the configuration for the Snap and its account:
Snap Account Configuration Snap Configuration 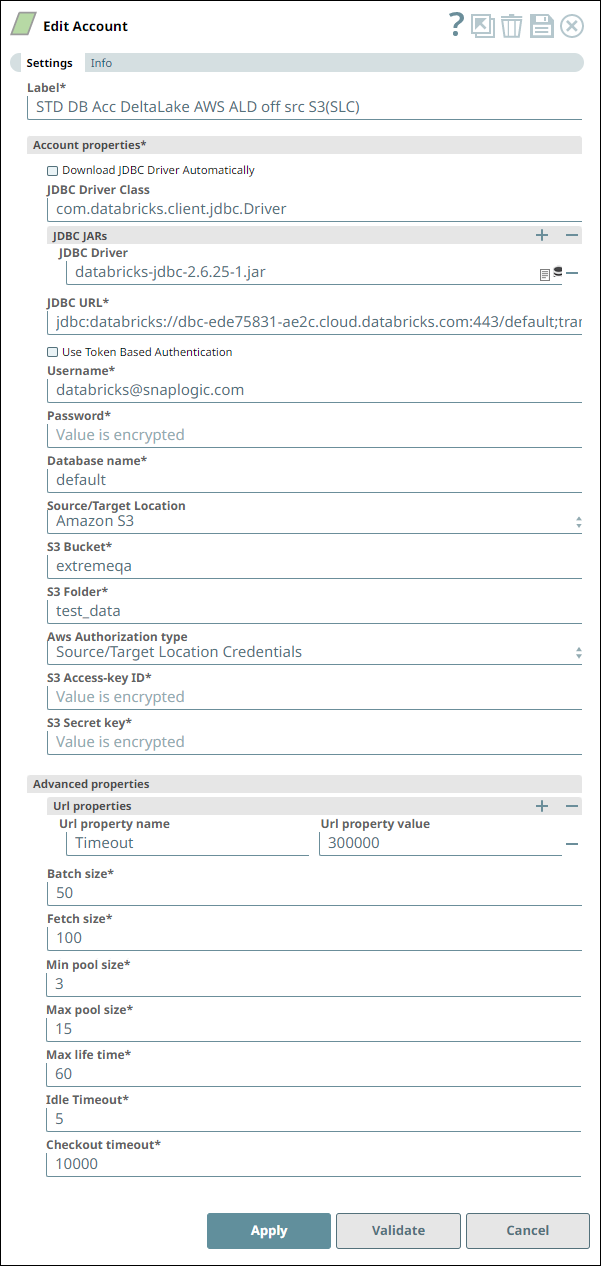
- For the account, we configure the Databricks Account to connect to our DLP instance
using the basic user credentials.
- As this is an unload operation, we choose the Target Location for saving the output CSV file as an AWS S3 location.
- We use the Location credentials authorization type (Access key ID and Secret Key) to access the target folder in this S3 location.
- We proceed with the default values for the fields in Advanced properties fieldset.
-
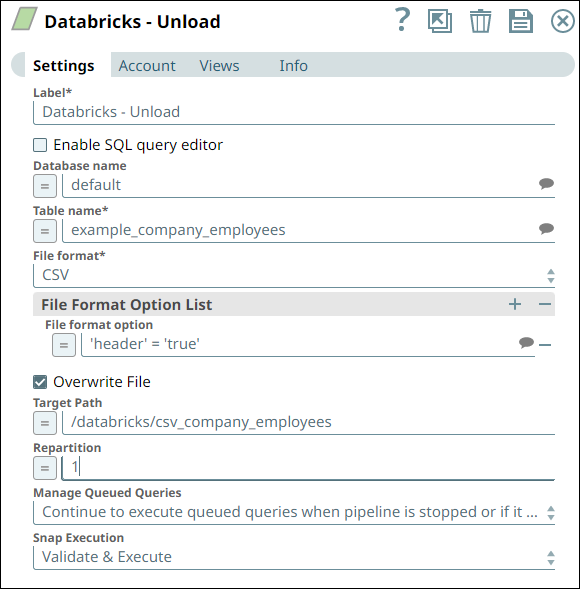
We specify the Database name and Table name (source data) for performing the unload operation. Alternatively, we can use the SQL query editor to specify these details in the form of an SQL statement.
- The File Format is CSV as we want a CSV file at the end of the unload operation.
-
We specify a File Format Option‘header’ = ‘true’ to include the header (column names from the table) in the output file.
-
- While specifying the target AWS S3 location path to store the CSV file, we also choose to:
- Not partition the data (all data in one CSV file) but
- Overwrite any existing files in that folder

Note:
To reuse the example pipelines:
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.