


Bulk Load Employee data from a CSV file into a DLP instance
Consider the scenario where we need the employee data from a CSV file to be fed into a DLP instance so that we can analyze the data.
.
Prerequisites
-
Configure the Bulk Load Snap account to connect to the AWS S3 service using Source Location Credentials to read the CSV file.
- We need two Snaps:
- Databricks Bulk Load: To load the data from the CSV file in an S3 location.
-
Databricks Select: To read the data loaded in the target table and generate some insights.
-
Configure the Databricks - Bulk Load Snap to load
employee data from the CSV into a new table, company_employees.
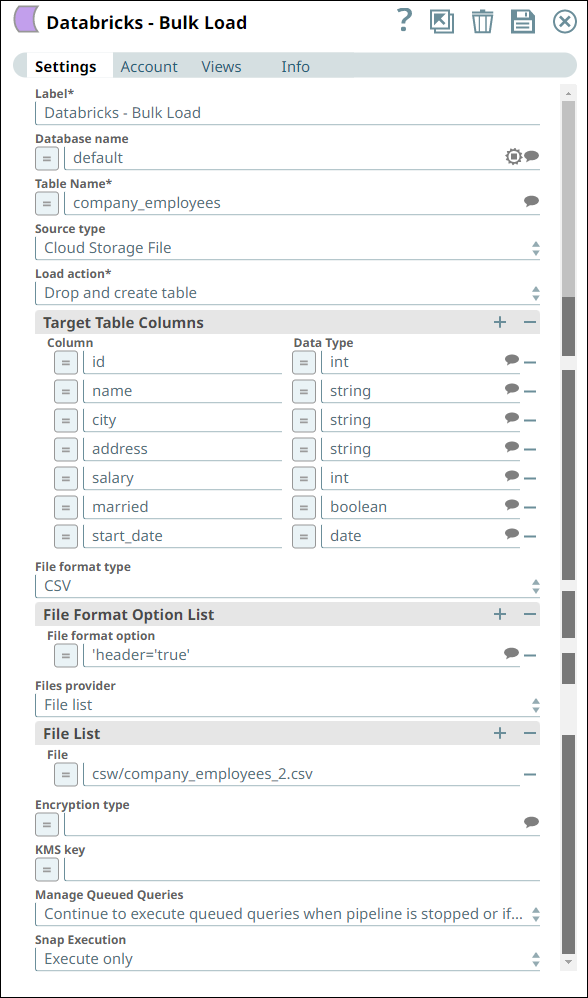
Here is how we do it:
- Select the Drop and create table as the Load action.
-
Define the schema for the new table in the Target Table Columns field set.
-
Choose the source data type and indicate that the file contains a valid header.
- Specify the file names (with relative paths, here) to load the data from.
- As our CSV file in the S3 location is not encrypted, we leave the corresponding fields blank.
-
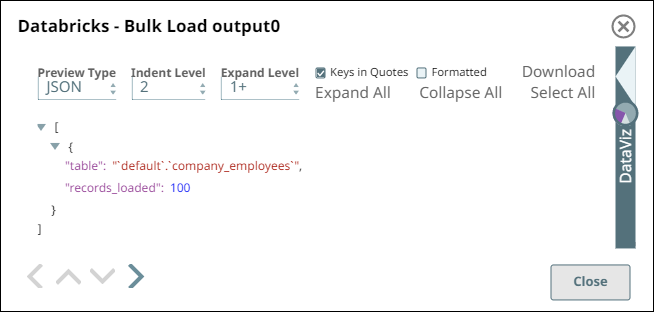
Run the pipeline—it loads the valid data into the target table and displays the new
table name and the number of records loaded.
-
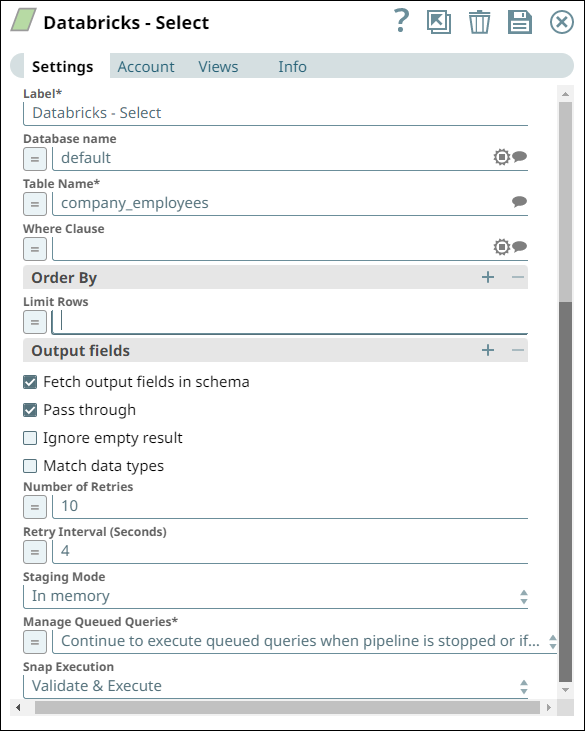
Next, to read the data from the new table in the DLP instance, use the Databricks -
Select Snap. Provide the Table name and configure the Snap with a WHERE clause,
salary < 500000.
-
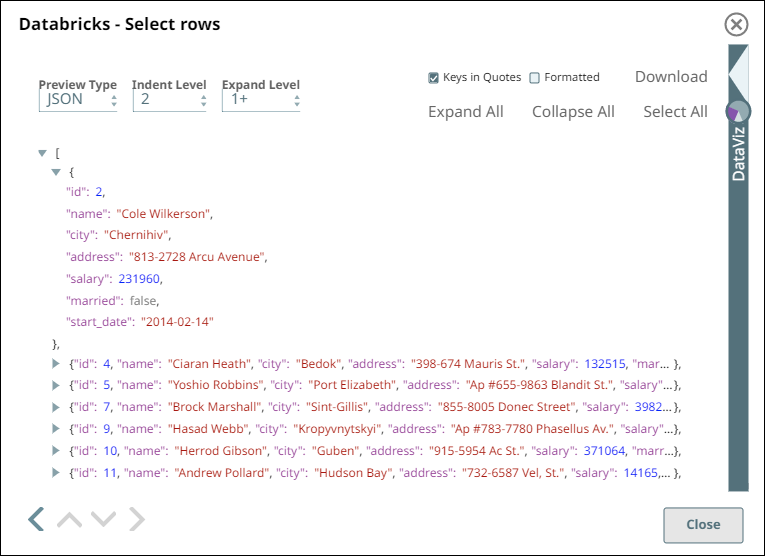
On validation, the Snap retrieves and displays the data from the company_employees
table that matches the WHERE condition specified.
- Download and import the pipeline into SnapLogic.
- Configure Snap accounts as applicable.
- Provide pipeline parameters as applicable.