


Load binary data
The following example pipeline demonstrates how you can convert the staged data into binary data using the binary file format before loading it into the Snowflake database.

-
Configure the Snowflake Execute Snap with this query:
select * from "PUBLIC"."EMP2" limit 25——this query reads 25 records from the Emp2 table.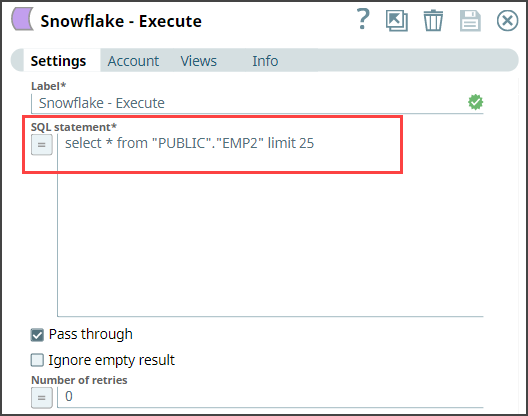
-
Configure the Mapper with the output from the upstream Snap by mapping the employee
details to the columns in the target table. Note that the Bio column is
the binary data type and the Text column is varbinary data type. Upon
validation, the Mapper Snap passes the output with the given mappings (employee
details) in the table.

-
Configure the Snowflake - Bulk Load Snap to load the records into Snowflake.
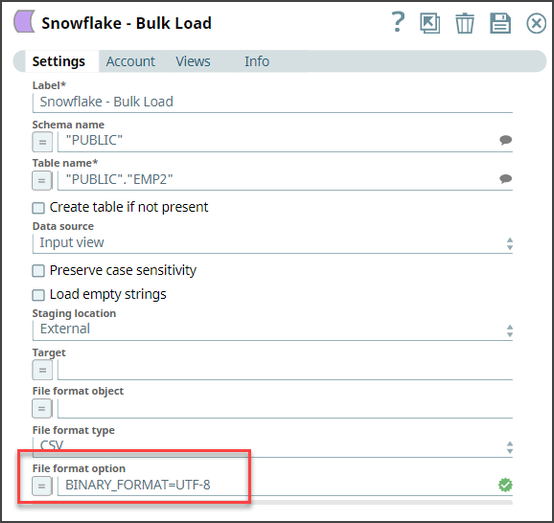
-
Set the File format option as BINARY_FORMAT=UTF-8 to enable the Snap to
encode the binary data before loading.
Upon validation, the Snap loads the database with 25 employee records. -
Connect the JSON
Formatter Snap to the Snowflake - Bulk Load Snap to transform the binary data to JSON
format, and finally write this output in S3 using the
File Writer
Snap.
