


JSON Formatter
Overview
You can use this Snap to read JSON document data from its input view, format and write it as JSON binary data to its output view. This is a Transform Snap type. A schema file can also be attached to the Snap that allows it to share the schema with upstream Snaps like the Mapper Snap.
- This is a Format-type Snap.
 Works in Ultra Tasks if Format each document property is selected.
Works in Ultra Tasks if Format each document property is selected.
Prerequisites
- A valid account with the required permissions.
Limitations and known issues
None.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | JSON document data to be formatted. | JSON Generator |
| Output | JSON binary data stream. | Group By Fields |
| Learn more about Error handling. | ||
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
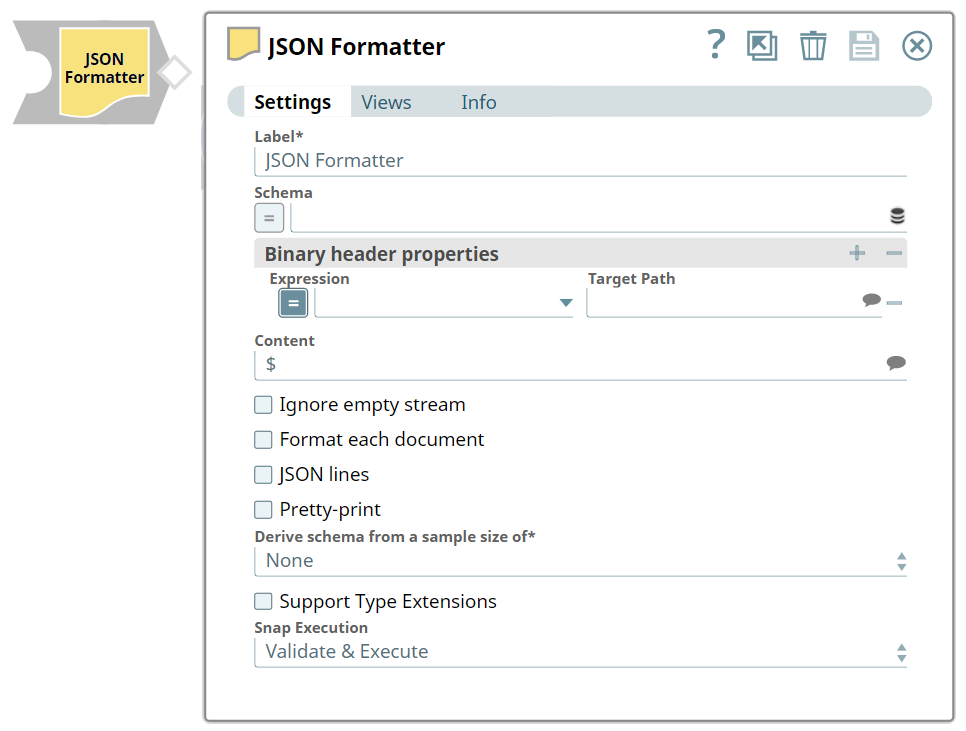
| Field/Field set | Type | Description |
|---|---|---|
Label
|
String |
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: JSON Formatter Example: Document Format |
| Schema | Button | Upload the JSON schema files, especially when the formatted JSON has to follow
a certain schema. This is particularly useful when used with the Mapper Snap, the
schema from the JSON Formatter Snap will be back-propagated to the Mapper Snap. This
is a suggestible property, click on the browse button to select file from your
project folder. Note: The pipeline should be validated once when the schema file has
been uploaded in order for the schema to be visible in the upstream Snap.
Default value: N/A Example: File number upload |
| Binary header properties | Use this field set to add properties to the binary document's header. The properties in the header of a binary document can be accessed in expression properties of downstream Snaps. For example, a 'content-location' property added to the header in this Snap can be referenced in the file name property of a File Writer snap with the expression: $['content-location']. When this Snap is configured to output a single binary document, the headers are computed from the first input document. When the "Format each document" option is enabled, the headers are computed separately for each binary output. | |
| Expression | String/Expression | Specify the function to be used to transform the data such as combine, concat
or flatten. Default value: N/A Example: |
| Target Path | String/Suggestion | Specify the target JSON path where the value from the expression will be
written. Default value: N/A Example: $person.firstname to write the field 'firstname' of the
'person' object. |
| Content | String/Suggestion | Specify the input object or field whose data must be written to the output
stream. Use $ to write the entire data. Default value: $ Example: $payload; $emp_salary; $group |
| Ignore empty stream | Checkbox | Select this checkbox to ignore empty stream when no document is received at the
input view throughout the Pipeline execution. Deselect this checkbox to enable the Snap to write an empty array to the output stream. Default status: Deselected |
| Format each document | Checkbox | Select this checkbox to enable the Snap to create one binary output stream for
every document on its input view. Deselect this checkbox to write one binary
output stream for all documents on its input view which are enclosed by a JSON
array element [ .. ]. See the example: Using JSON Formatter Snap to render outputs
from Group By Snaps, for a simple but less-frequent scenario. Note: For Data
Groups in Input View Select this checkbox along with JSON lines checkbox and set the Content field to $group to output one document per group with member in the group as a separate JSON line. Default status: Deselected |
| JSON lines | Checkbox | Select this checkbox to enable the Snap to write all documents to a single
output file, with each document appearing as a single line followed by a new line.
This field cannot be used with Pretty-print checkbox. See the
example: Using JSON Formatter Snap to render outputs from Group By Snaps, for a
simple but less-frequent scenario. Note: For Data Groups in Input
View Select this checkbox along with Format each document checkbox and set the Content field to $group to output one document per group with member in the group as a separate JSON line. Default status: Deselected |
| Pretty-print | Checkbox | Select this checkbox to format the output to make it more readable/printable.
Default status: Deselected |
| Derive Schema from a Sample Size of * | Dropdown list | Select the size of the number of initial input documents to be used when
deriving the schema to be added to the binary output header. The sizing that you
choose depends on the uniformity of the source schema. For example, if the schema is
uniform across the documents, then choose Small. If the schema differs from
document to document, then choose a larger size (Medium or Large) to
attain a more accurate sampling of your schema. The performance impact on the
Pipeline execution/validation is greater, the larger the sample size is. If you
select None, then the schema is not sampled. Default value: None Example: Small |
| Support Type Extensions | Checkbox/Expression | Select this checkbox to enable the Snap to format/parse the Snaplogic-specific
syntax indicating objects of the special types, such as byte arrays and date objects
in JSON. Default status: Deselected |
| Snap execution
|
Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Validate & Execute Example: Execute only |
Troubleshooting
Unexpected character ('{' (code 123)
Possible Causes
The array entries in the JSON file do not follow the syntax. A comma ',' is expected before the beginning of every second array—'{'.
Possible Solutions
Verify the array at the row and column mentioned beside the error message using the Edit JSON feature and add a comma appropriately.