


Trainer (Classification)
Overview
You can use this Snap to build model for a classification dataset. In the Snap's settings, you can select the target field in the dataset, algorithm, and configure parameters for the selected algorithm.
 Transform-type Snap
Transform-type Snap-
 Does not support Ultra Tasks
Does not support Ultra Tasks
Prerequisites
- The data from upstream Snap must be in tabular format (no nested structure).
- This Snap automatically derives the schema (field names and types) from the first document. Therefore, the first document must not have any missing values.
Limitations and known issues
None.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input |
The Snap accepts atmost one input view. |
|
| Output |
The Snap produces atmost one output views: |
|
| Learn more about Error handling. | ||
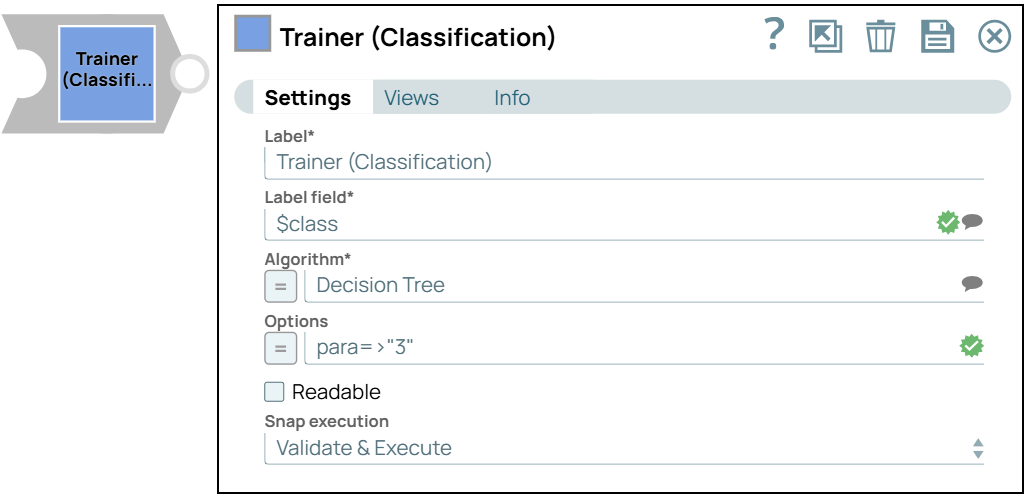
Snap settings
- Expression icon (
 ): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more.
): Allows using
JavaScript syntax to access SnapLogic Expressions to set field values dynamically (if
enabled). If disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values.
): Populates a
list of values dynamically based on your Snap configuration. You can select only one
attribute at a time using the icon. Type into the field if it supports a comma-separated
list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field/Field set | Type | Description |
|---|---|---|
Label
|
String |
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Trainer (Classification) Example: Classification training |
| Label field | String/Suggestion | Required.Specify the target or class field of
the dataset that the model will use during the training process. This field
represents the expected output values that the model learns to predict based on the
input data. During inference, the model predicts this field as its output. Default value: N/A Example: $class |
| Algorithm | String |
Required. Enter the classification algorithm that builds the model. Default value: K-Nearest Neighbors Example: Naive Bayes |
| Options | String/Expression |
Specify the parameters to configure the selected algorithm. These options may include hyperparameters or specific settings that influence the algorithm's behavior. Default value: N/A Example: max_depth=5, criterion="gini"/> |
| Readable | Checkbox | When selected, the output model is made more interpretable, focusing on
readability for end-users. Default status: Deselected |
| Snap execution | Dropdown list | Choose one of the three modes in which the Snap executes. Available options
are:
|
Options for Algorithms
This section lists all applicable parameters for each algorithm along with their default values.
| Option Name | Option Data Type | Default Value | Description |
|---|---|---|---|
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| binary_splits | boolean | false | Enable binary splits. |
| collapse_tree | boolean | true | Set to allow collapsing the tree. |
| confidence_factor | float | 0.25 | Set the confidence threshold for pruning. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| do_not_mask_split_point_actual_value | boolean | false | Set whether the split point actual value is to be masked. |
| min_num_obj | int | 2 | Set the minimum number of instances per leaf. |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| num_folds | int | 3 | Set the number of folds for reduced error pruning. One fold is used as pruning set. |
| reduced_error_pruning | boolean | false | Enable reduced error pruning. This is false if the unpruned parameter is set to true. |
| save_instance_data | boolean | false | Set whether the instance data is to be saved. If set to true, it does not clean up after the tree has been built. |
| seed | int | 1 | Set the seed for random data shuffling. |
| subtree_raising | boolean | true | Enable sub-tree raising. |
| unpruned | boolean | false | Enable using unpruned tree. This is false if the reduced_error_pruning parameter is set to true. |
| use_laplace | boolean | false | Allow Laplace smoothing for predicted probabilities. |
| use_md_correction | boolean | true | Allow MDL correction for info gain on numeric attributes. |
| Option Name | Option Data Type | Default Value | Description |
|---|---|---|---|
| knn | int | 1 | Set the number of neighbors the learner will use. |
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| cross_validate | boolean | false | Set whether hold-one-out cross-validation will be used to select the best k-value. |
| distance_weighting | enum [weight_none, weight_inverse, weight_similarity] | weight_none | Set the distance weighting method used. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| mean_squared | boolean | false | Set whether the mean squared error is used rather than mean absolute error when doing cross-validation. |
| nearest_neighbours_search_algorithm | enum [LinearNNSearch, BallTree, CoverTree, KDTrees, FilteredNeighbourSearch] | LinearNNSearch | Set the nearest neighbour search algorithm to be used for finding nearest neighbor(s). |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| window_size | int | 0 | Set the maximum number of instances allowed in the training pool. |
| Option Name | Option Data Type | Default Value | Description |
|---|---|---|---|
| knn | int | 1 | Set the number of neighbors the learner will use. |
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| cross_validate | boolean | false | Set whether hold-one-out cross-validation will be used to select the best k-value. |
| distance_weighting | enum [weight_none, weight_inverse, weight_similarity] | weight_none | Set the distance weighting method used. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| mean_squared | boolean | false | Set whether the mean squared error is used rather than mean absolute error when doing cross-validation. |
| nearest_neighbours_search_algorithm | enum [LinearNNSearch, BallTree, CoverTree, KDTrees, FilteredNeighbourSearch] | LinearNNSearch | Set the nearest neighbour search algorithm to be used for finding nearest neighbor(s). |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| window_size | int | 0 | Set the maximum number of instances allowed in the training pool. |
| Option Name | Option Data Type | Default Value | Description |
|---|---|---|---|
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| matx_its | int | -1 | Set the maximum number of iterations. |
| num_decimal_places | int | 4 | Set the number of decimal places. |
| ridge | double | 1.00E-08 | Sets the ridge in the log-likelihood. |
| use_conjugate_gradient_descent | boolean | false | Sets whether conjugate gradient descent is used. |
| Option Name | Data Type | Default Value | Description |
|---|---|---|---|
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| use_kernel_estimator | boolean | false | Use kernel density estimator rather than normal distribution for numeric attributes. This is false if use_supervised_discretization is set to true. |
| use_supervised_discretization | boolean | false | Use supervised discretization to process numeric attributes. This is false if use_kernel_estimator is set to true. |
| Option Name | Data Type | Default Value | Description |
|---|---|---|---|
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| c | double | 1 | Set the complexity constant C. |
| build_calibration_models | boolean | false | Set whether to fit calibration models to SVM outputs. |
| checks_turned_off | boolean | false | Disable all checks. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| epsilon | double | 1.00E-12 | Set the epsilon for round-off error. |
| filter_type | enum [filter_none, filter_normalize, filter_standardize] | filter_normalize | Set how the training data will be transformed. |
| kernel | enum [PolyKernel, NormalizedPolyKernel, PrecomputedKernelMatrixKernel, Puk, RBFKernel, StringKernel] | PolyKernel | Specify the Kernel to use. |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| num_folds | int | -1 | Set the number of folds for the internal cross-validation. |
| random_seed | int | 1 | Set the random number seed. |
| tolerance_parameter | double | 1.00E-03 | Set the tolerance parameter. |
| Option Name | Data Type | Default Value | Description |
|---|---|---|---|
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| Option Name | Data Type | Default Value | Description |
|---|---|---|---|
| bag_size_percent | int | 100 | Specify the size of each bag, as a percentage of the training set size. |
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| break_ties_randomly | boolean | false | Set whether to break ties randomly when several attributes look equally good. |
| calc_out_of_bag | boolean | false | Set whether to calculate the out-of-bag error. |
| compute_attribute_importance | boolean | false | Set whether to compute and output attribute importance (mean impurity decrease method). |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| max_depth | int | 0 | Set the maximum depth of the tree, 0 for unlimited. |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| num_execution_slots | int | 1 | Set the number of execution slots. |
| num_features | int | 0 | Set the number of attributes to randomly investigate. |
| num_iterations | int | 100 | Set the number of iterations. |
| seed | int | 1 | Set the seed for the random number generator. |
| store_out_of_bag_predictions | boolean | false | Set whether to store out-of-bag predictions in the internal evaluation object. |
| Option Name | Data Type | Default Value | Description |
|---|---|---|---|
| batch_size | int | 100 | Set the preferred batch size for batch prediction. |
| do_not_check_capabilities | boolean | false | Enable capability-check. |
| learning_rate | double | 0.3 | Set the learning rate for the backward propagation. The value should be between 0 - 1. |
| momentum | double | 0.2 | Set the momentum rate for the backward propagation algorithm. The value should be between 0 - 1. |
| num_decimal_places | int | 2 | Set the number of decimal places. |
| seed | int | 0 | Set the value used to seed the random number generator. |
| validation_set_size | int | 0 | Set the percentage size of the validation set to use to terminate training. The value should be between 0 - 1. |
| validation_threshold | int | 20 | Set the number of consecutive increases of error allowed for validation testing before training terminates. |