


Calculate common word frequency
This example pipeline demonstrates how to calculate the frequency of the most common words in a dataset with the Tokenizer and Bag of Words Snaps.
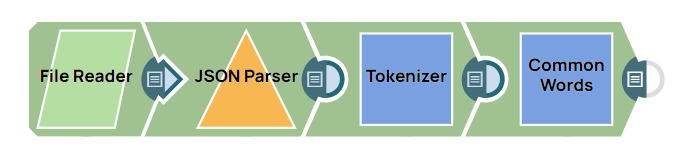
-
Configure the
File Reader
Snap to read the
contents of the Employee data.json file.
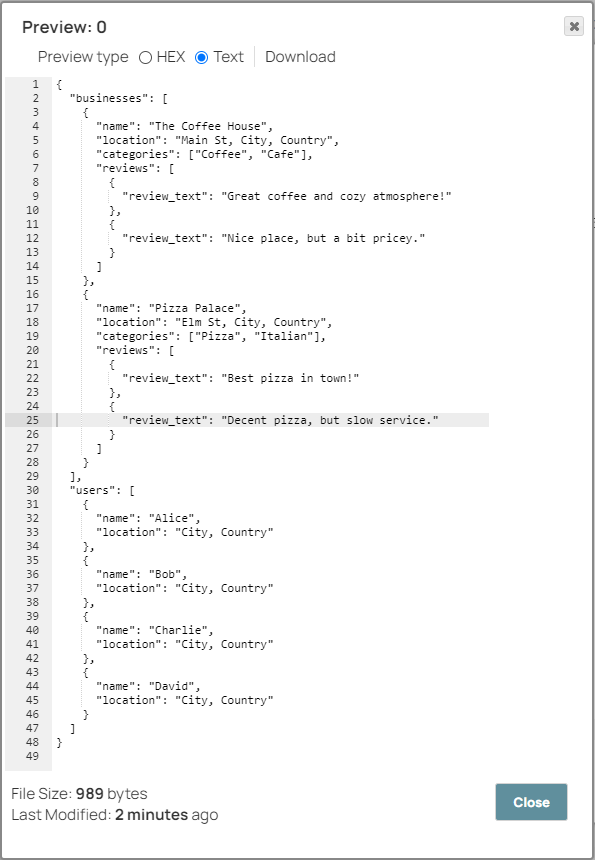
On validation, the Snap displays the read contents of the yelp_dataset.txt file and offers a binary stream as output.
File Reader Snap configuration File Reader Snap Preview 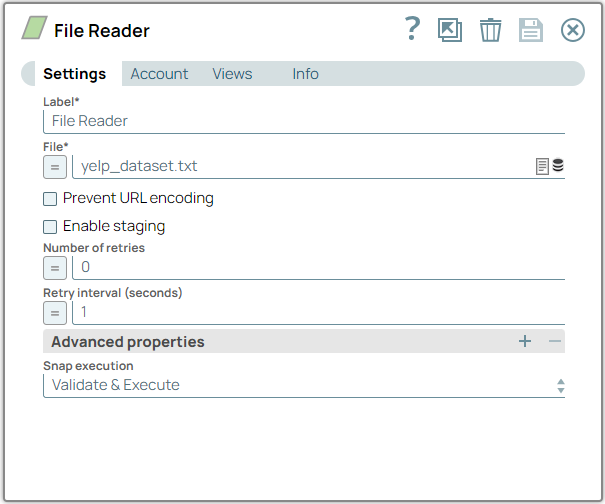
-
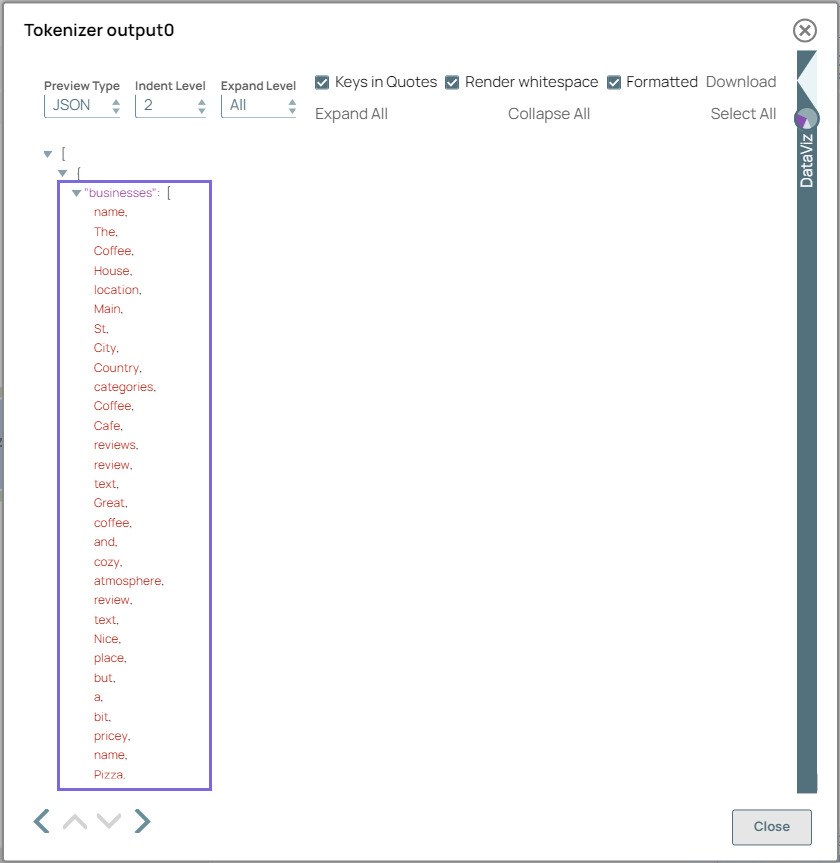
Configure the Tokenizer Snap with
$businesses to read from the business data.
On validation, the Snap displays the content from $businesses that will be tokenized and output as an array of tokens.
Tokenizer Snap configuration Tokenizer Snap output 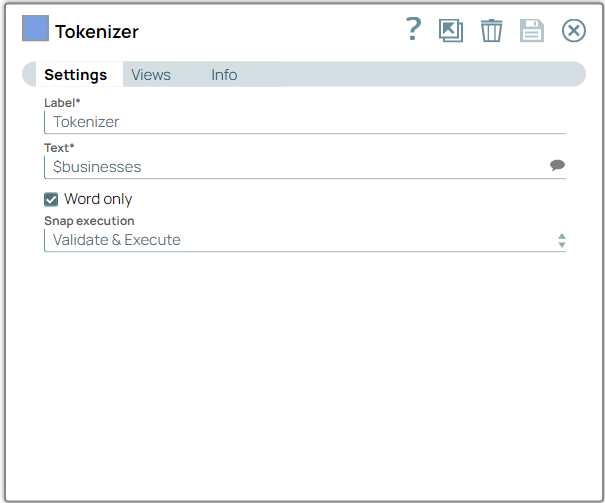
-
Configure the Common Words Snap to compute the
frequency of each word that appears in the array of tokens.
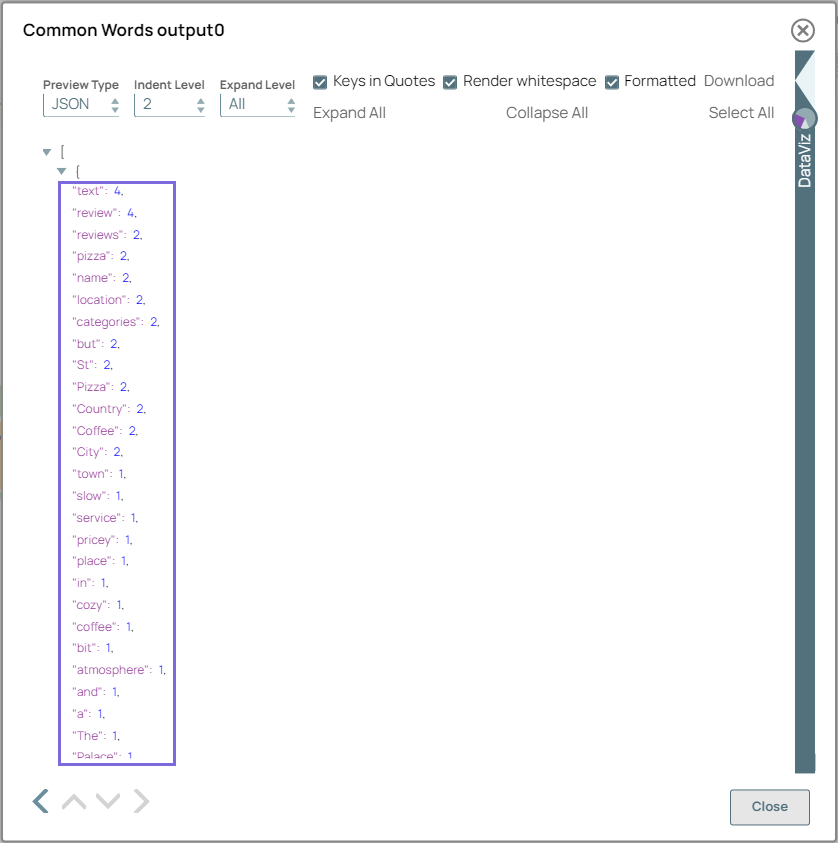
On validation, the Snap displays a detailed summary of the word frequencies, providing insights into the most common words in the dataset.
Common Words Snap configuration Common Words Snap output 
Note: After the data is generated, you can use Snaps such as the Filter and Aggregate Snaps for advanced processing. You can also use AgentCreator to integrate machine learning models.
- Download and import the pipeline into the SnapLogic Platform.
- Configure Snap accounts, as applicable.
- Provide pipeline parameters, as applicable.