


Use Case: Predict kickstarter success
Overview
This use case demonstrates the application of machine learning in predicting the success of crowdfunding projects on platforms like Kickstarter.
Problem scenario
Crowdfunding platforms, such as Kickstarter, allow innovators to raise funds. With millions of backers and hundreds of thousands of projects, predicting project success can be challenging. If we could predict success, we could help increase the success rate of future projects by adjusting various factors.
Description
Using a dataset of over 300,000 Kickstarter projects containing general project information, we will train a model to classify projects as successful or failed. For this demonstration, we use a sample of 20,000 projects.
Objectives
- Profiling: Generate statistics using the Profile Snap from the ML Analytics Snap Pack.
- Data Preparation: Prepare the dataset using the ML Data Preparation Snap Pack.
- AutoML: Use the AutoML Snap to build and select the best-performing model.
- Cross Validation: Use the Cross Validator (Classification) Snap to evaluate different machine learning algorithms for predictive accuracy.
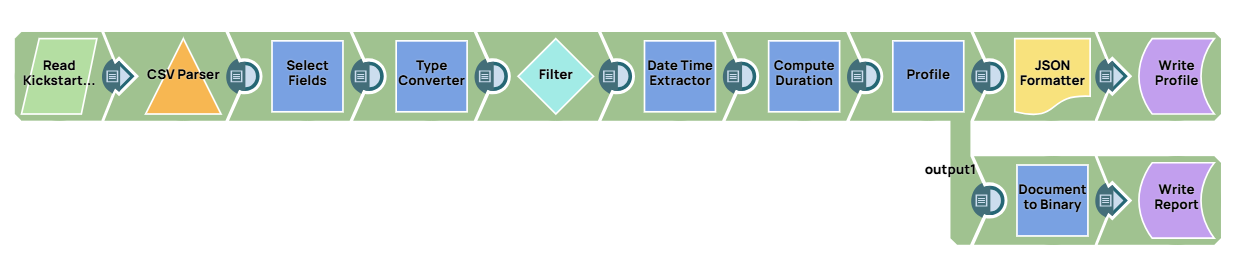
Profiling
We first prepare the data by selecting relevant fields, converting data types, and filtering out irrelevant projects.
Using the Mapper Snap, we select and rename fields, followed by the Type Converter Snap to derive data types. We filter projects with statuses other than successful or failed. The Date Date Time Extractor Snap converts dates to epoch format, and the Mapper Snap calculates project duration.
Finally, we use the Profile Snap to compute statistics, saving the results as a JSON file on SnapLogic File System (SLFS).
Data preparation
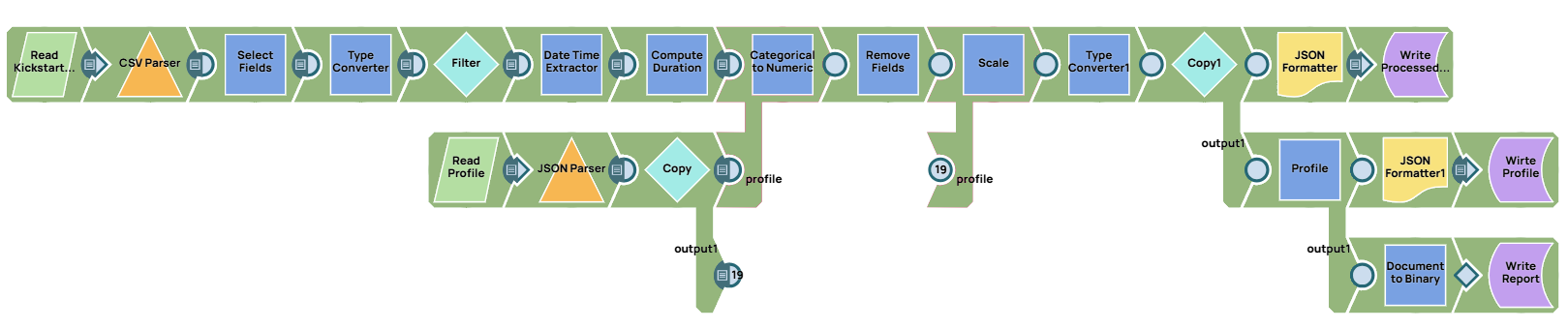
Next, we transform the dataset for machine learning.
The first Mapper and Type Converter Snaps are reused from the previous pipeline. We read the profiling statistics, then convert categorical data to numeric using integer encoding and one-hot encoding, making the data ready for machine learning. We scale numeric fields to a range of 0 to 1 for consistency.
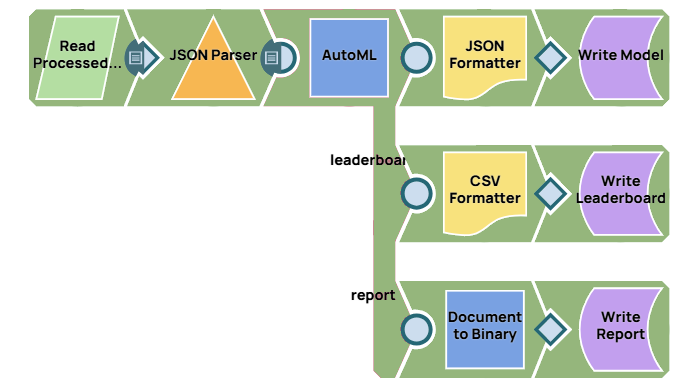
AutoML
In this pipeline, we use the AutoML Snap to build multiple models within a set time and resource limit, choosing the one with the best performance.
The File Reader Snap reads the processed dataset. The AutoML Snap then builds up to 10 models within a 3,600-second time limit. This Snap supports Weka and H2O engines and various algorithms. The XGBoost model achieved the best performance with an AUC of 0.74.
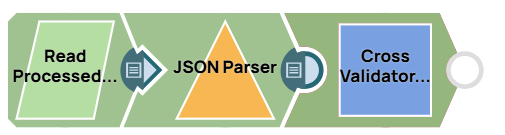
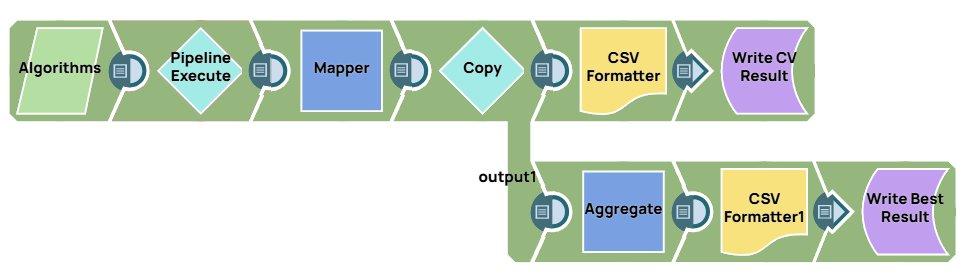
Cross validation
This pipeline performs 10-fold cross-validation with different classification algorithms, allowing us to compare accuracy across models.
The parent pipeline uses the pipeline Execute Snap to call a child pipeline with specified parameters (e.g., algorithm name). The child pipeline performs cross-validation on the dataset, and the results are aggregated in the parent pipeline to find the algorithm with the highest accuracy. Logistic regression performed best on this dataset with an accuracy of 66.6%, improving upon the baseline accuracy of 59.5%.
Building API
To deploy this pipeline as a REST API, click the calendar icon in the toolbar and choose either a Triggered Task or Ultra Task.
Triggered Task: Suitable for batch processing.
Ultra Task: Recommended for real-time API access.
To get the URL, open the Create Task window, select Show tasks in this project in Manager, and click Details.
API testing
In this pipeline, a sample request is generated with the JSON Generator Snap and sent to the Ultra Task via the REST Post Snap. The Mapper Snap extracts and formats the response.
The final response includes prediction results and confidence scores, allowing users to assess project success probability.