


Execute PySpark script
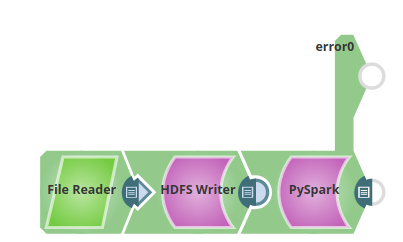

The following PySpark Script is executed:
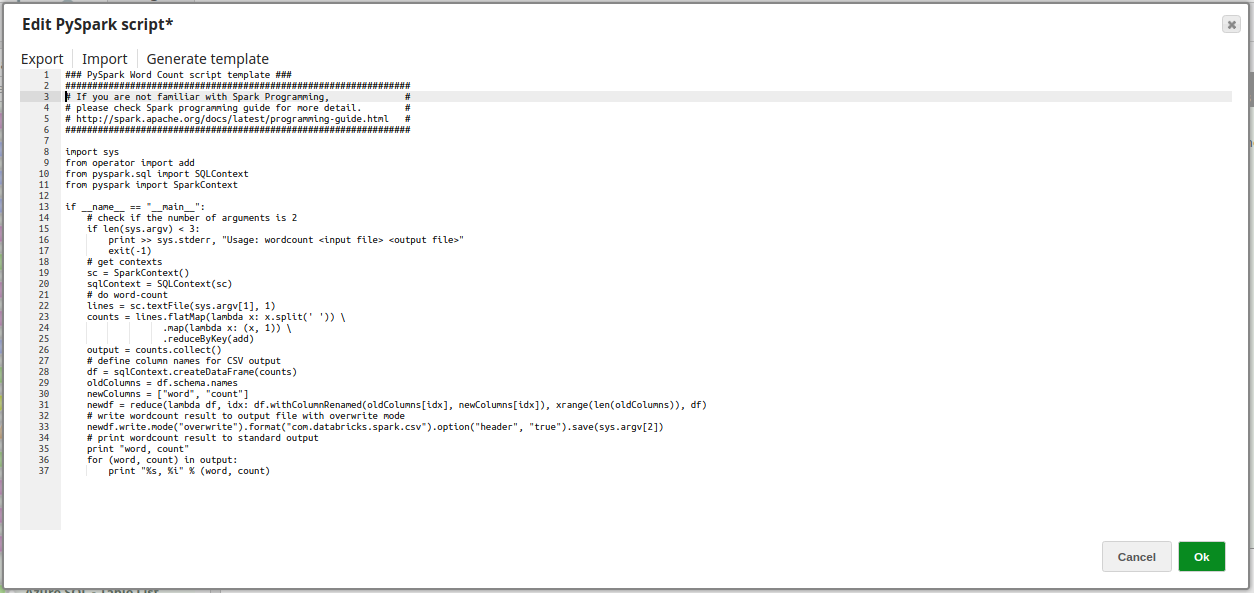
PySpark Word Count script template
### PySpark Word Count script template ###
################################################################
# If you are not familiar with Spark Programming, #
# please check Spark programming guide for more detail. #
# http://spark.apache.org/docs/latest/programming-guide.html #
################################################################
import sys
from operator import add
from pyspark.sql import SQLContext
from pyspark import SparkContext
if __name__ == "__main__":
# check if the number of arguments is 2
if len(sys.argv) < 3:
print >> sys.stderr, "Usage: wordcount <input file> <output file>"
exit(-1)
# get contexts
sc = SparkContext()
sqlContext = SQLContext(sc)
# do word-count
lines = sc.textFile(sys.argv[1], 1)
counts = lines.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x, 1)) \
.reduceByKey(add)
output = counts.collect()
# define column names for CSV output
df = sqlContext.createDataFrame(counts)
oldColumns = df.schema.names
newColumns = ["word", "count"]
newdf = reduce(lambda df, idx: df.withColumnRenamed(oldColumns[idx], newColumns[idx]), xrange(len(oldColumns)), df)
# write wordcount result to output file with overwrite mode
newdf.write.mode("overwrite").format("com.databricks.spark.csv").option("header", "true").save(sys.argv[2])
# print wordcount result to standard output
print "word, count"
for (word, count) in output:
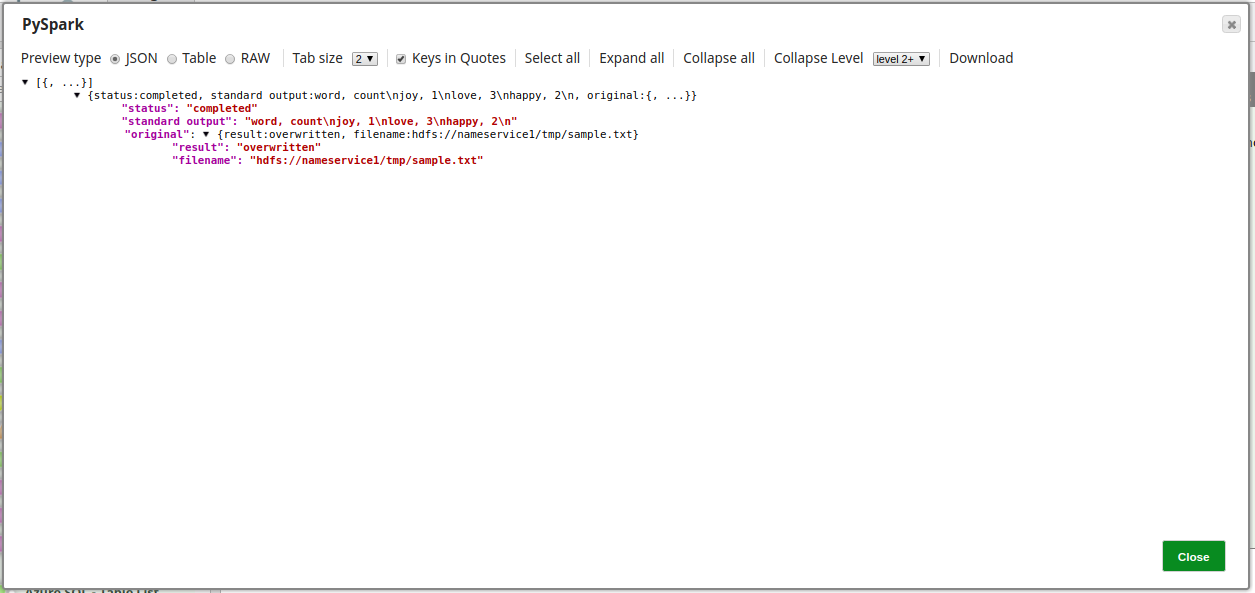
print "%s, %i" % (word, count)On validation, the Snap produces output as shown below:
Note:
To reuse the example pipelines:
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.