


Insert data from a Snowflake table into a DLP table
Consider the scenario where we want to load data available in a Snowflake table into a table in your Databricks instance with the table schema in tact. This example demonstrates how we can use the Databricks - Insert Snap to achieve this result:
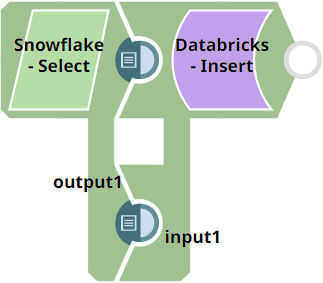
- In this Pipeline, we configure the Snowflake - Select
Snap from the Snowflake Snap Pack with the appropriate
account, zero input views, and open two output views—one for capturing the rows data and
the other for capturing the table schema (as metadata). See the sample configuration of
the Snap and its account below:
Snowflake - Select Snap Settings Snowflake - Select Snap Views 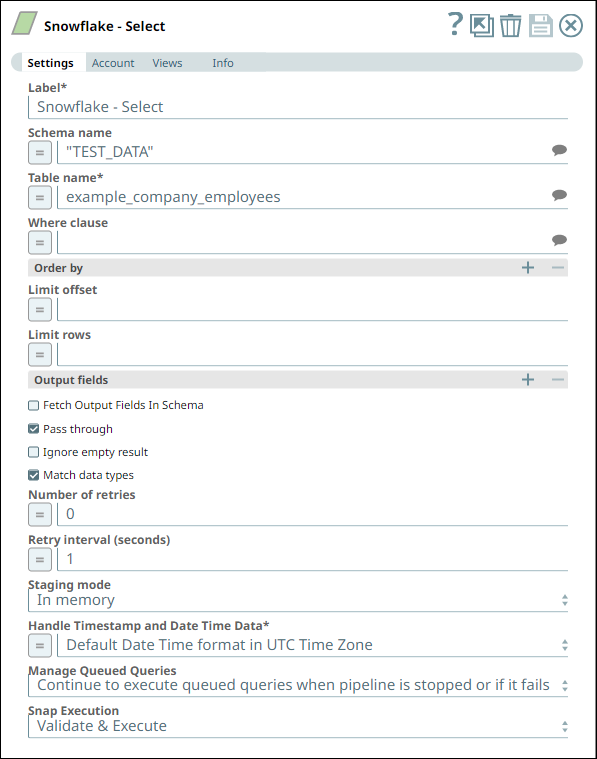
Account Settings for Snowflake - Select Snap Notes 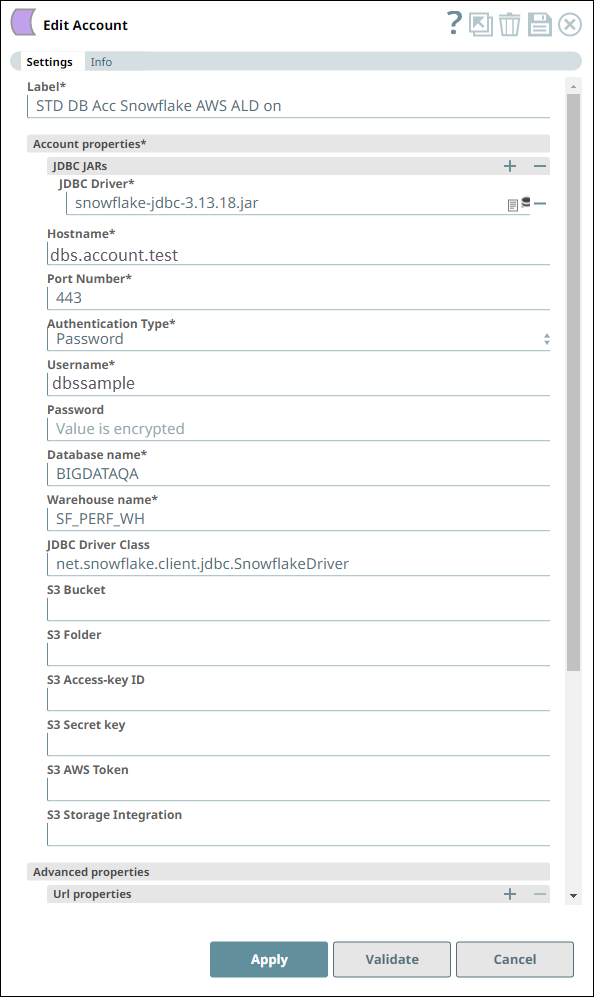
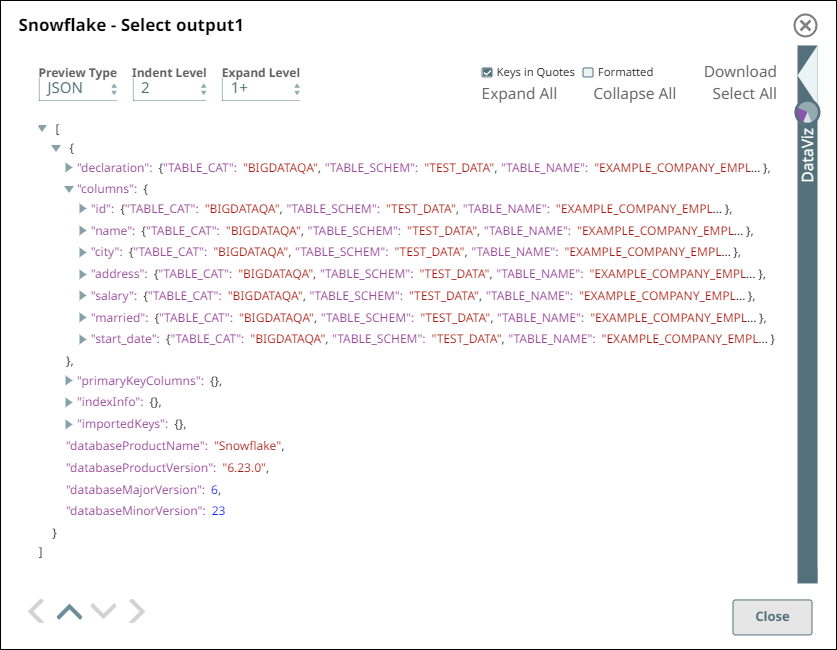
We configure the Snap to fetch the table schema (output1) and the table data (rows) from the example_company_employees2 table in the Snowflake instance.
The Snap uses a Snowflake JDBC driver and the corresponding basic auth credentials to connect to the Snowflake instance hosted on the AWS cloud.
- Upon validation, the Snap displays the table schema and a sample set of records from
the specified table in its two output views. During runtime, the Snap retrieves all data
from the example_company_employees2 table that match the Snap’s configuration
(WHERE conditions, LIMIT, and so on).
Snowflake - Select Snap Output View for Table data Snowflake - Select Snap Output View for Table Schema 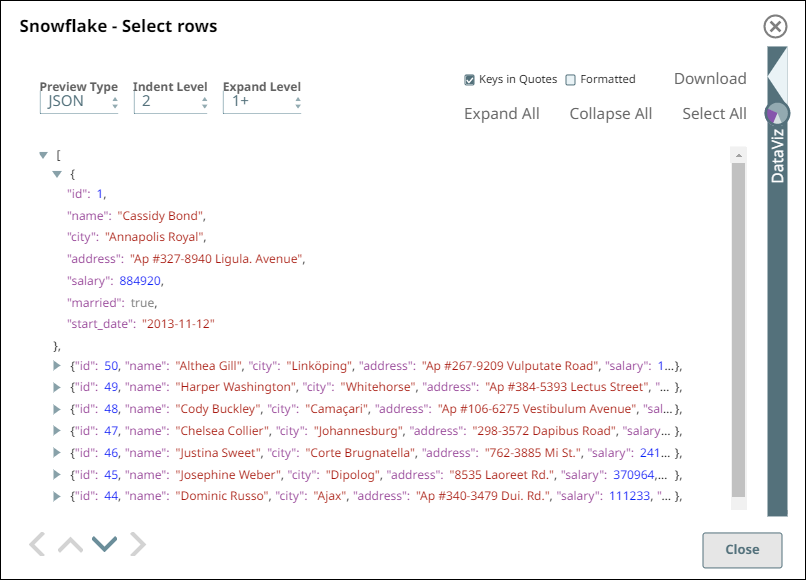
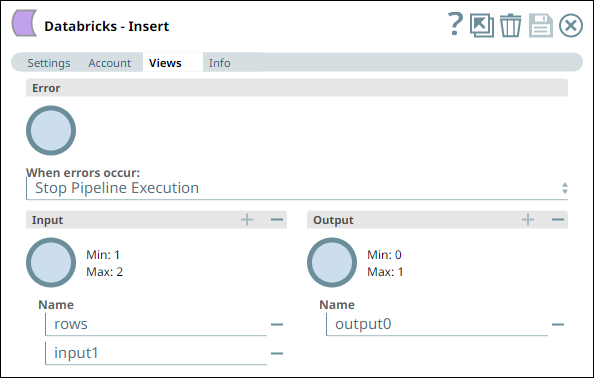
- Similarly, we use a Databricks - Insert Snap with the
appropriate account and two input views to consume the two outputs coming from the Databricks - Select Snap. See the sample configuration of
the Snap and its account.
Databricks - Insert Snap Settings Databricks - Insert Snap Views 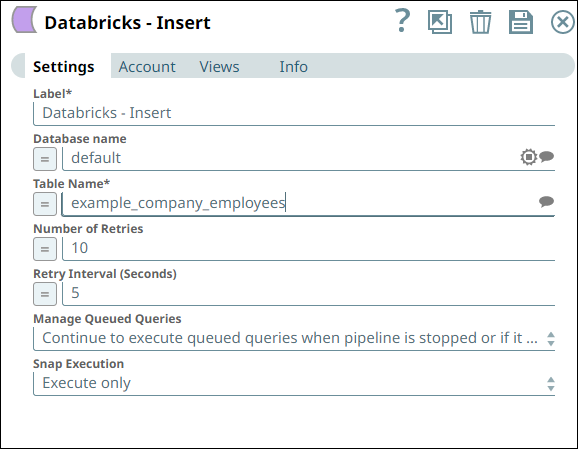
Account Settings for Databricks - Insert Snap Notes 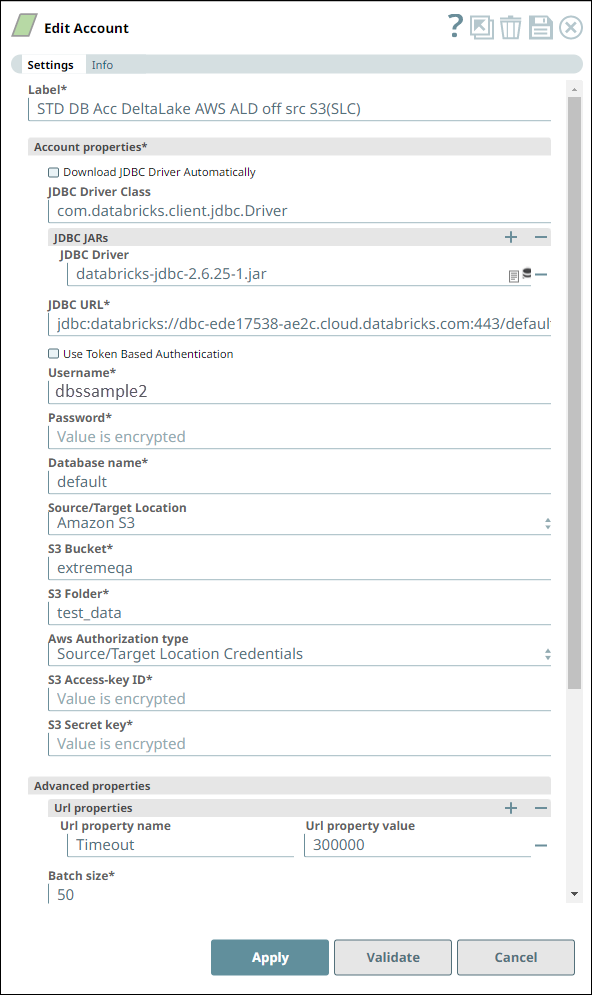
We configure the Snap to consume the table schema (output1) and the table data (rows) from the example_company_employees table in the Snowflake instance.
The Snap uses a Databricks JDBC driver and the corresponding basic auth credentials to connect to the DLP (target) instance hosted on the AWS cloud.
The Snap is configured to perform the Insert operation only during Pipeline execution and hence, it does not display any results during validation. Upon Pipeline Execution, the Snap creates a new table example_company_employees2 in the specified DLP database using the schema from the Snowflake - Select Snap and populates the retrieved rows data in this new table.
- Download and import the SLP file into your Environment.
- Configure Snap accounts.
- Provide Pipeline parameters, if any.