


HDFS Writer
The HDFS Writer Snap reads a binary data stream from its input view and writes a file in HDFS (Hadoop File System).
Overview
- This is a Write-type Snap.
 Works in Ultra Tasks
Works in Ultra Tasks
Limitations
- File names with the following special characters are not supported in the HDFS Writer Snap: '+', '?', '/', ':'.
Known issues
The upgrade of Azure Storage library from v3.0.0 to v8.3.0 has caused the following issue when using the WASB protocol:
When you use invalid credentials for the WASB protocol in Hadoop Snaps (HDFS Reader, HDFS Writer, ORC Reader, Parquet Reader, Parquet Writer), the pipeline does not fail immediately, instead it takes 13-14 minutes to display the following error:
reason=The request failed with error code null and HTTP code 0. , status_code=errorLearn more about Azure Storage library upgrade.
Snap views
| Type | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has exactly one binary input view. It accepts binary input data from upstream Snaps such as formatters. | |
| Output | This Snap has at most one document output view. It provides
output with the filename and file action taken (overwritten,
created, or ignored). Example output: |
|
| Learn more about Error handling. | ||
Supported Accounts
Snap settings
| Field/Field set | Description |
|---|---|
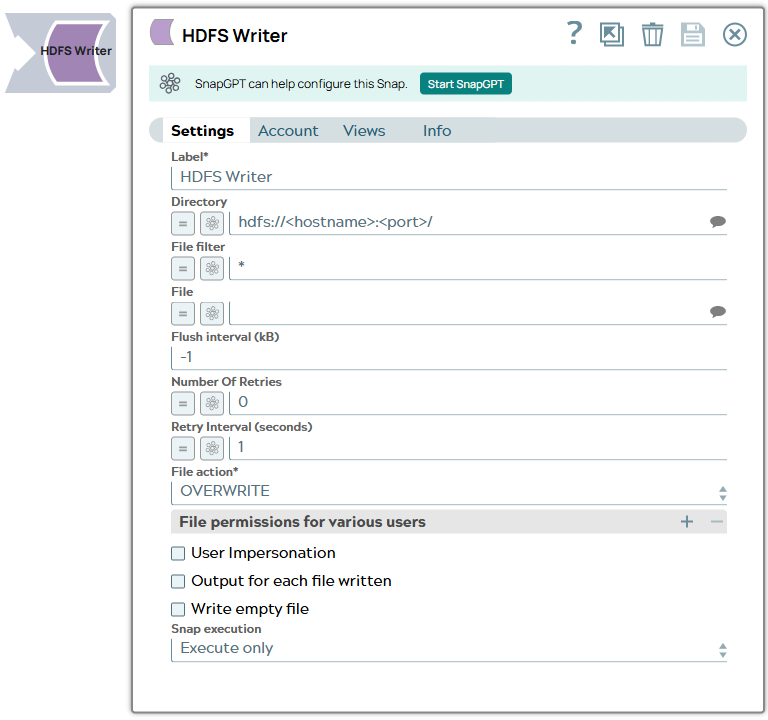
| Label*
|
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: HDFS Writer Example: HDFS Writer |
| Directory
|
Specify the URL for HDFS directory. It should start with hdfs file protocol in the following format:
The Directory property is not used in the Pipeline execution or preview and used only in the Suggest operation. When you click the Suggestion icon, the Snap displays a list of subdirectories under the given directory. It generates the list by applying the value of the Filter property. Note: SnapLogic automatically appends
azuredatalakestore.net to the store name
you specify when using Azure Data Lake; therefore, you do not
have to add azuredatalakestore.net to the URI
while specifying the directory.Default value: hdfs://<hostname>:<port>/ Example:
|
| File
filter
|
Specify the Glob filter pattern. Note: Use glob patterns to display a list of directories or files
when you click the Suggest icon in the Directory or File
property. A complete glob pattern is formed by combining the
value of the Directory property with the Filter property. If the
value of the Directory property does not end with "/", the Snap
appends one, so that the value of the Filter property is applied
to the directory specified by the Directory property.
Default value: * |
| File
|
Specify the filename or a relative path to a file under the directory given in the Directory property. It should not start with a URL separator "/". The File property can be a JavaScript expression which will be evaluated with values from the input view document. When you click the Suggest icon, it will display a list of regular files under the directory in the Directory property. It generates the list by applying the value of the Filter property. Default value: N/A Example:
|
| Flush interval
(kB)
|
Specify the flush interval in kilobytes to flush a specified size of data during the file upload. This Snap can flush the output stream each time a given size of data is written to the target file server. Note: If the Flush interval is 0, the Snap flushes maximum
frequency after each byte block is written. The larger the flush
interval, the less frequent are the flushes. This field is useful
if the file upload experiences an intermittent failure. However,
more frequent flushes result in slower file upload. The default
value of -1 indicates no flush during the upload.
Default value: -1 Example: 0 |
| Number Of
Retries
|
Specify the maximum number of attempts to be made to receive a response. Note:
Default value: 0 Example: 1 |
| Retry Interval
(seconds)
|
Specify the time interval between two successive retry requests. A retry happens only when the previous attempt resulted in an exception. Default value: 1 Example: 5 |
| File action*
|
Select an action to perform if the specified file already exists:
Note: The Append operation is supported for FILE, SFTP, FTP,
and FTPS protocols only. For any other protocols that are not
supported by Append, we recommend that you use the
File Operation
, File Writer, and File Delete Snaps andfollow this procedure.
Note: This approach might involve disk overhead, therefore ensure that you have enough disk space in your system. Default value: Overwrite Example: Append |
| File permissions for various users |
Use this field set to select the user and the desired file permissions. Note:
Limitations with File Permissions for Various Users
|
| User
type
|
It should be 'owner' or 'group' or 'others'. Each row can have only one user type and each user type should appear only once. Please select one from the suggested list. Default value: N/A Example: owner, group, others |
| File
permissions
|
It can be any combination of {read, write, execute} separated by '+' character. Please select one from the suggested list. Default value: N/A Example: read, write, execute, read+write, read+write+execute |
| User
Impersonation
|
Select this check box to enable user impersonation. Note: Hadoop allows you to configure proxy users to access HDFS on
behalf of other users; this is called impersonation. When user
impersonation is enabled on the Hadoop cluster, any jobs
submitted using a proxy are executed with the impersonated user's
existing privilege levels rather than those of the superuser
associated with the cluster. For more information on user
impersonation in this Snap, see the section on User Impersonation
below.
Default value: Deselected |
| Output for each file
written
|
Enables you to produce a different output document for each file
that is written. If the Snap receives multiple binary input data
and the File expression property is dynamically evaluated
to a filename by using the By default, the Snap produces only one output document with a filename that corresponds to the last file that was written. Default value: Deselected |
| Write empty
file
|
Select this checkbox to write an empty file to all the supported protocols when the binary input document has no data. Default value: Deselected |
| Snap Execution
|
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Validate & Execute Example: Execute only |
Troubleshooting
Writing to S3 files with HDFS version CDH 5.8 or later
When running HDFS version later than CDH 5.8, the Hadoop Snap Pack may fail to write to S3 files. To overcome this, make the following changes in the Cloudera manager:
- Go to HDFS configuration.
- In Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml, add an entry with the following details:
- Name: fs.s3a.threads.max
- Value: 15
- Click Save.
- Restart all the nodes.
- Under Restart Stale Services, select Re-deploy client configuration.
- Click Restart Now.