


Headless Ultra Tasks
Headless Ultra Tasks are an Ultra Task pipeline design for continuous, listener-driven data processing. Unlike Low-latency Ultra Tasks, which receive inbound HTTP requests through a FeedMaster, Headless Ultra Tasks are based on pipelines that start with a listening Snap—such as a message queue consumer or event subscriber—that continuously polls or subscribes to an external data source. A FeedMaster is not required. This design is well-suited for event-driven integrations where data originates from external systems and must be processed continuously without an inbound HTTP request.
Use cases
Headless Ultra Tasks are appropriate when your integration requires continuous, unattended data consumption from a source that pushes or queues events. Common use cases include:
- Message queue consumption: Continuously read and process messages from JMS, Kafka, Amazon SQS, or Azure Service Bus queues.
- Event-driven integrations: React to Salesforce platform events or SAP IDoc and RFC events in real time.
- IoT data ingestion: Process high-volume sensor or device data arriving over MQTT topics.
- Cloud pub/sub processing: Consume events published to Amazon SNS, Google Pub/Sub, or Google Sheets Subscribe and route them to downstream systems.
- File system change detection: Use the File Poller Snap to watch a directory and trigger processing when new files arrive.
Pipeline design
A Headless Ultra pipeline has no unconnected input or output views. The pipeline starts with a listening Snap connected directly to an external data source, and ends with one or more destination Snaps that write or forward the consumed data. Because no FeedMaster is involved, the pipeline runs as a self-contained, continuously executing process.
The following Snaps support Headless Ultra mode and can serve as the listening source in a Headless Ultra pipeline:
| Snap Pack | Snap |
|---|---|
| Amazon SNS | Subscribe Topic |
| Amazon SQS | SQS Consumer |
| Azure Service Bus | ASB Consumer |
| Binary | File Poller |
| Google Pub/Sub | Subscribe |
| Google Sheets | Google Sheets Subscribe |
| JMS | JMS Consumer |
| Kafka | Kafka Consumer |
| MQTT | MQTT Consumer |
| Salesforce | Salesforce Subscriber |
| SAP | |
| Zuora | Zuora Subscribe |
Design considerations
- Because multiple instances may run concurrently during Snaplex state transitions—even when the configured instance count is one—use the acknowledgement facilities provided by the message queue or source system to avoid processing the same event multiple times.
- Headless Ultra does not support the Autoscale based on FeedMaster queue instance setting. This option requires a FeedMaster, which Headless Ultra does not use.
- Headless Ultra does not support the Max In-Flight configuration setting.
- Headless Ultra does not support the
ultra.max_redelivery_countSnaplex property for configuring document redelivery retries.
Examples
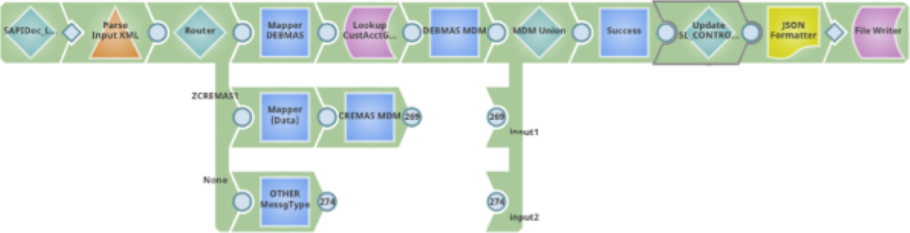
Change data capture with SAP IDoc
This pipeline uses the SAP IDoc Document Listener Snap to continuously poll an SAP system for IDoc change events. Because the pipeline does not receive documents from a FeedMaster, there is no unconnected output view. Incoming IDoc documents are transformed and written to a destination data table to capture the changes.
JMS message queue consumer
This pipeline uses the JMS Consumer Snap to continuously poll a JMS message queue. The pipeline reads messages from the queue and writes the data to a destination—such as a File Writer Snap—without requiring an inbound HTTP request or a connected input view.