

Principal Component Analysis (PCA)
Perform Principal Component Analysis (PCA) on an input document
This Snap performs Principal Component Analysis (PCA) on an input document and outputs a document containing fewer dimensions (or columns). PCA is a dimension-reduction technique that can be used to reduce a large set of variables to a small set that still contains most of the information in the original set. In simple terms, PCA attempts to find common factors in a given dataset, and ranks them in order of importance. Therefore, the first dimension in the output document accounts for as much of the variance in the data as possible, and each subsequent dimension accounts for as much of the remaining variance as possible. Thus, when you reduce the number of dimensions, you significantly reduce the amount of data that the downstream Snap must manage, making it faster.
PCA is widely used to perform tasks such as data compression, exploratory data analysis, pattern recognition, and so on. For example, you can use PCA to identify patterns that can help you isolate specific species of flowers that are more closely related than others.
How does it work?
The PCA Snap performs two tasks:
- It analyzes data in the input document and creates a model that
- Reduces the number of dimensions in the input document to the number of dimensions specified in the Snap.
- Retains the amount of variance specified in the Snap.
- It runs the model created in the step above on the input data and emits a document containing the processed output, offering a simplified view of the data, making it easier for you to identify patterns in it.
 Transform-type Snap
Transform-type Snap Works in Ultra Tasks only when the Snap has two input views and one output view.
Works in Ultra Tasks only when the Snap has two input views and one output view.
Prerequisites
- The input data must be in a tabular format.
Limitations
- The PCA Snap does not work with data containing nested structures.
Known issues
None.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has at most two document input views.
|
|
| Output | This Snap has at most two document output views:
|
|
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
Snap settings
- Expression icon (
 ): JavaScript
syntax to access SnapLogic Expressions to set field values dynamically (if enabled). If
disabled, you can provide a static value. Learn more.
): JavaScript
syntax to access SnapLogic Expressions to set field values dynamically (if enabled). If
disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Account configuration.
): Populates a
list of values dynamically based on your Account configuration. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field / field set | Type | Description |
|---|---|---|
| Label | String |
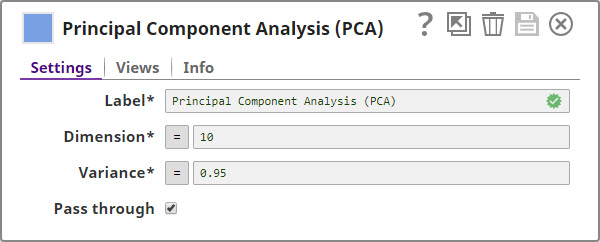
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Principal Component Analysis (PCA) Example: PCA |
| Dimension | String/Expression |
Required. The maximum number of dimensions or columns that you want in the output. Minimum value: 0 Maximum value: Undefined Default value: 10 |
| Variance | String/Expression |
Required. The minimum variance that you want to retain in the output documents. Minimum value: 0 Maximum value: 1 Default value: 0.95 |
| Pass through | Checkbox | Select this checkbox to include all the categorical input fields in the output.
Default status: Selected |