

Deduplicate
Overview
You can use this Snap to remove duplicate records from input documents. When you use multiple matching criteria to deduplicate your data, the Snap evaluates each criterion separately and then aggregates the results. This Snap ignores fields with empty strings and whitespaces as no data.
 Transform-type Snap
Transform-type Snap Does not support Ultra Tasks
Does not support Ultra Tasks
Prerequisites
None.
Limitations and known issues
None.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap supports one document input view. It processes a document with data containing duplicate records. | |
| Output |
This Snap supports up to two document output views.
|
|
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
Snap settings
- Expression icon (
 ): JavaScript
syntax to access SnapLogic Expressions to set field values dynamically (if enabled). If
disabled, you can provide a static value. Learn more.
): JavaScript
syntax to access SnapLogic Expressions to set field values dynamically (if enabled). If
disabled, you can provide a static value. Learn more. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Account configuration.
): Populates a
list of values dynamically based on your Account configuration. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field / field set | Type | Description |
|---|---|---|
| Label | String |
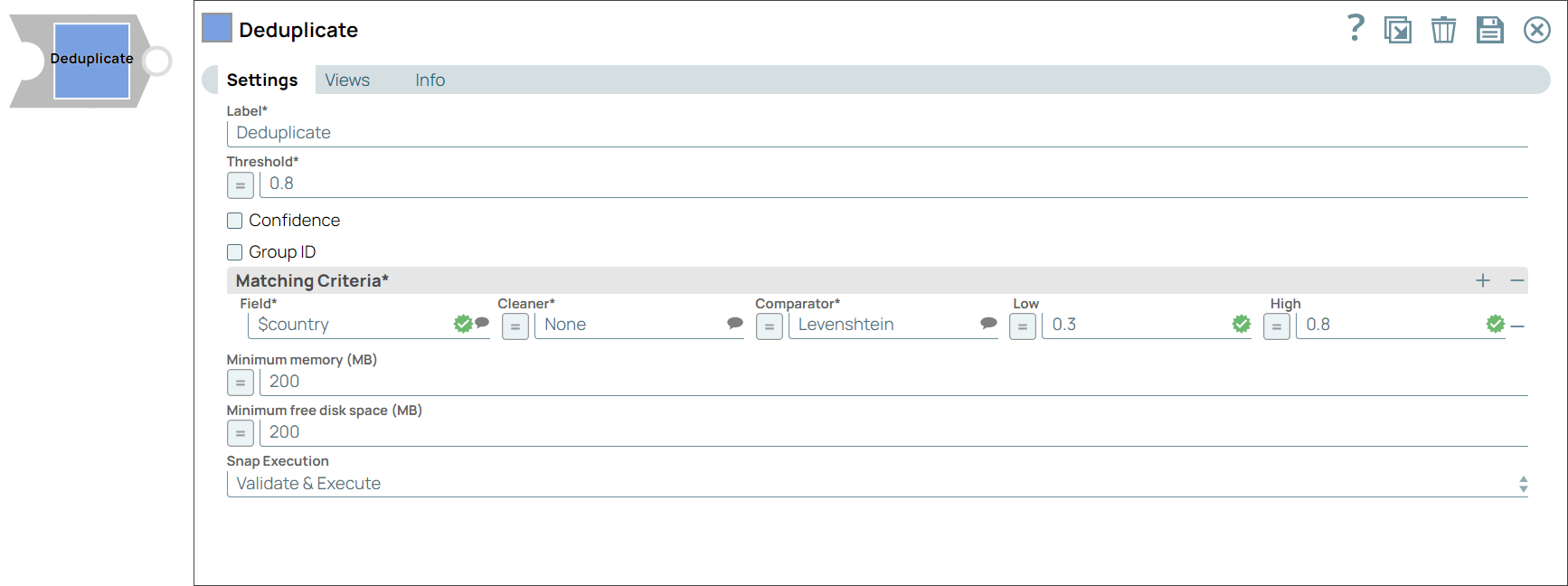
Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Deduplicate Example: Deduplicate address lines |
| Threshold | Decimal |
Required. The minimum confidence required for documents to be considered duplicates using the matching criteria. Minimum value: 0 Maximum value: 1 Default value: 0.8 Example: 0.95 |
| Confidence | Checkbox |
Select this checkbox to include each match's confidence levels in the output. Default status: Deselected |
| Group ID | Checkbox |
Select this checkbox to include the group ID for each record in the output. Default status: Deselected |
| Matching Criteria |
Enables you to specify the settings you want to use to match input documents with the matching criteria. |
|
| Field | JSONPath |
The field in the input dataset that you want to use for matching and identifying duplicates. Default value: None. Example: $name |
| Cleaner | String |
Select the cleaner that you want to use on the selected fields. Important:
A cleaner makes comparison easier by removing variations from data, which are not likely to indicate genuine differences. For example, a cleaner might strip everything except digits from a ZIP code. Or, it might normalize and lowercase text. Depending on the nature of the data in the identified input fields, you can select the kind of cleaner you want to use from the options available:
Default value: None. Example: Text |
| Comparator | Dropdown list |
Important:
A comparator compares two values and produces a similarity indicator, which is represented by a number that can range from 0 (completely different) to 1 (exactly equal). Choose the comparator that you want to use on the selected fields, from the drop-down list:
Default value: Levenshtein Example: Metaphone |
| Low | Decimal | A decimal value representing the level of probability of the input documents to be matched if the specified fields are completely unlike.
Important: If this value is left empty, a value of 0.3 is applied automatically.
Default value: None. Example: 0.1 |
| High | Decimal | A decimal value representing the level of probability of the input documents to be matched if the specified fields are a complete match.
Important: If this value is left empty, a value of 0.95 is applied automatically.
Default value: None. Example: 0.8 |
| Minimum memory (MB) | Integer/Expression |
Specify a minimum cut-off value for the memory the Snap must use when processing the documents. If the available memory is less than the
specified value, the Snap stops execution and displays an exception to prevent the system from running out of memory.
Default value: 200 Example: 1000 |
| Minimum free disk space (MB) | Integer/Expression |
Specify the minimum free disk space required for the Snap to execute. If the free disk space is less the than the specified value, the
Snap stops execution and displays an exception to prevent the system from running out of disk space.
Default value: 200 Example: 1000 |
| Snap execution | Dropdown list |
Select one of the three modes in which the Snap executes.
Available options are:
Default value: Validate & execute Example: Execute only |
Temporary files
During execution, data processing on Snaplex nodes occurs principally in-memory as streaming and is unencrypted. When processing larger datasets that exceed the available compute memory, the Snap writes unencrypted pipeline data to local storage to optimize the performance. These temporary files are deleted when the pipeline execution completes. You can configure the temporary data's location in the Global properties table of the Snaplex node properties, which can also help avoid pipeline errors because of the unavailability of space. Learn more about Temporary Folder in Configuration Options.