


Databricks - Select
Overview
You can use this Snap to fetch data from a database by providing the table name from a Databricks Lakehouse Platform (DLP) instance. You can read and process this output data from a downstream Snap.
 Read-type Snap
Read-type Snap Does not support Ultra Tasks
Does not support Ultra Tasks
Prerequisites
- Valid access credentials to a DLP instance with adequate access permissions to perform the action in context.
- Valid access to the external source data in one of the following: Azure Blob Storage, ADLS Gen2, DBFS, GCP, AWS S3, or another database (JDBC-compatible).
Limitations
Snaps in the Databricks Snap Pack do not support array, map, and struct data types in their input and output documents.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | A JSON document containing the input values for the Snap’s configuration. | |
| Output |
The default output view contains the data fetched by running the SELECT statement on the source location. A second view can be added to show the metadata for the table as a Document. The metadata document can then be fed into the second input view of Databricks - Merge Into or Bulk Load Snaps so that the table is created in Databricks with a similar schema as the source table. |
|
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
Snap settings
- Expression icon (
 ): Allows using pipeline parameters to set field
values dynamically (if enabled). SnapLogic Expressions are not supported. If
disabled, you can provide a static value.
): Allows using pipeline parameters to set field
values dynamically (if enabled). SnapLogic Expressions are not supported. If
disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration.
You can select only one attribute at a time using the icon.
Type into the field if it supports a comma-separated list of values.
): Populates a
list of values dynamically based on your Snap configuration.
You can select only one attribute at a time using the icon.
Type into the field if it supports a comma-separated list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field / Field set | Type | Description |
|---|---|---|
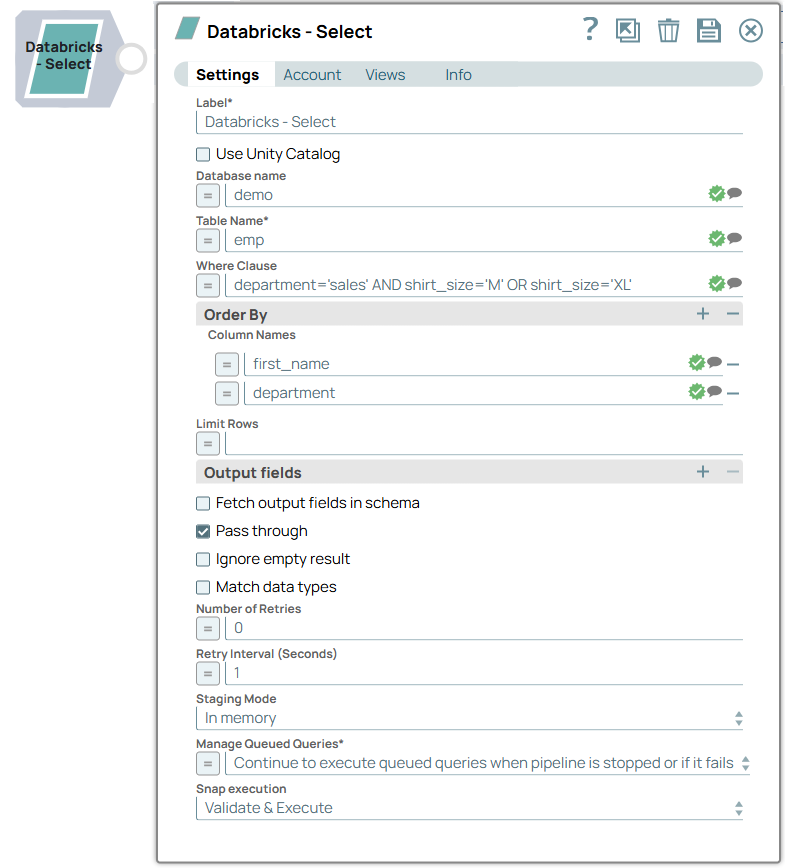
| Label | String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Databricks - Select Example: DLP Select |
| Use unity catalog | Checkbox | Select this checkbox to use the Unity catalog to access data from the
catalog. Default status: Deselected |
| Catalog name | String/Expression/ Suggestion | Appears when you select Use unity catalog. Specify the name of the catalog for using the unity catalog. Default value: hive_metastore Example: xyzcatalog |
| Database name | String/Expression/ Suggestion | Enter your DLP database name for the SELECT statement to read the data from. Default value: N/A Example: SalesDB |
| Table name | String/Expression/ Suggestion | Required. Enter your table name for the SELECT
statement to read the data from. Default value: N/A Example: leads_to_sales_conversion |
| Where clause | String/Expression/ Suggestion | Specify the WHERE clause (condition) for the SELECT statement to apply while
retrieving the data from the DLP table. Default value: N/A Example: LEAD_CITY=Delware |
| Order by | You can use this field set to define the order in
which the retrieved rows are populated in the output. Click the Add fieldset row
icon |
|
| Column names | String/Expression/ Suggestion | Click the Suggest icon Note: If you do not specify a sort order in this fieldset, the Snap
returns data in the same order as the DLP table. Default value: None. Example: LEAD_REGION |
| Limit rows | String/Expression | Specify the number of rows of data you want the Snap to retrieve from the
table. Note: If you do not specify a limit in this fieldset, the Snap returns
entire data in the the DLP table during execution. See Snap Execution field
below for the limits during Pipeline validation. Default value: None. Example: 100 |
| Output fields | You can use this fieldset to define the list of
columns to be retrieved in the output. Click the Add fieldset row icon |
|
| Output field | String/Expression/ Suggestion | Click the Suggest icon Note: If you do not specify any output fields, the Snap returns
data from all the columns in the DLP table. Default value: None. Example: LEAD_EXP_VALUE |
| Fetch Output Fields In Schema | Checkbox | Select this checkbox to retrieve schema information from the table for only the
output fields specified above. If not selected, the Snap retrieves schema
information from all fields available in the table. Default status: Deselected Example: Not selected |
| Pass through | Checkbox | Select this checkbox to include the input document as-is under the
original key of this Snap's output.Default status: Selected Example: Not selected |
| Ignore empty result | Checkbox | Select this checkbox to prevent the Snap from writing any document to its
output view when no records are retrieved for the specified Snap configuration.
Note: When no records are retrieved and the Pass through checkbox is
selected, the Snap output contains the input document in the
original key.Default status: Deselected Example: Selected |
| Match data types | Checkbox | With at least one output field selected in the Output fields fieldset,
select this checkbox to match the data types of the columns with those retrieved
when no output field is specified (as in SELECT * FROM... ). The
output preview will be in the same format as the one when the statement
SELECT * FROM <specified_table> is run and all the contents of
the table are displayed.Default status: Deselected Example: Selected |
| Number of Retries | Integer/Expression | Specifies the maximum number of retry attempts when the Snap fails to write. Note:
If the value is larger than 0, the Snap first downloads the target file into a temporary local file. If any error occurs during the download, the Snap waits for the time specified in the Retry interval and attempts to download the file again from the beginning. When the download is successful, the Snap streams the data from the temporary file to the downstream Pipeline. All temporary local files are deleted when they are no longer needed. Ensure that the local drive has sufficient free disk space to store the temporary local file. Minimum value: 0 Default value: 3 Example: 0 |
| Retry Interval (seconds) | Integer/Expression | Specifies the minimum number of seconds the Snap must wait before each retry
attempt. Minimum value: 1 Default value: 1 Example: 3 |
| Staging Mode | Dropdown list | Select this property to specify the location where the in-flight records should
be stored while using the Retry option. Options available are: On disk: The records are stored on the disk. In Memory: The records are stored in the internal memory. Default value: In Memory Example: On disk |
| Manage Queued Queries | Dropdown list | Select this property to determine whether the Snap should continue or cancel
the execution of the queued Databricks SQL queries when you stop the
Pipeline. Note: If you select Cancel queued queries when pipeline is stopped or
if it fails, then the read queries under execution are cancelled, whereas
the write type of queries under execution are not cancelled. Databricks internally
determines which queries are safe to be cancelled and cancels those
queries. Warning: Due to an issue with DLP, aborting an ELT
Pipeline validation (with preview data enabled) causes only those SQL statements
that retrieve data using bind parameters to get aborted while all other static
statements (that use values instead of bind parameters) persist.
To avoid this issue, ensure that you always configure your Snap settings to use bind parameters inside its SQL queries. Default value: Continue to execute queued queries when pipeline is stopped or if it fails. Example: Cancel queued queries when pipeline is stopped or if it fails |
| Snap execution | Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Example: Validate & Execute |
Troubleshooting
| Error | Reason | Resolution |
|---|---|---|
| Missing property value | You have not specified a value for the required field where this message appears. | Ensure that you specify valid values for all required fields. |