


Databricks - Run Job
Overview
You can use this Snap to automate the execution of a set of tasks or processes within a Databricks workspace. It triggers the task and periodically checks its progress. The Snap stops after the job is complete, but if you cancel the pipeline before the task finishes, the Snap requests to terminate the task.
 Write-type Snap
Write-type Snap Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
- Valid client ID.
- A valid account with the required permissions.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | Requires a valid task name, notebook path, and cluster-info. | |
| Output | Executes the selected notebook. | |
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
Snap settings
- Expression icon (
 ): Allows using pipeline parameters to set field
values dynamically (if enabled). SnapLogic Expressions are not supported. If
disabled, you can provide a static value.
): Allows using pipeline parameters to set field
values dynamically (if enabled). SnapLogic Expressions are not supported. If
disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration.
You can select only one attribute at a time using the icon.
Type into the field if it supports a comma-separated list of values.
): Populates a
list of values dynamically based on your Snap configuration.
You can select only one attribute at a time using the icon.
Type into the field if it supports a comma-separated list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field / Field set | Type | Description |
|---|---|---|
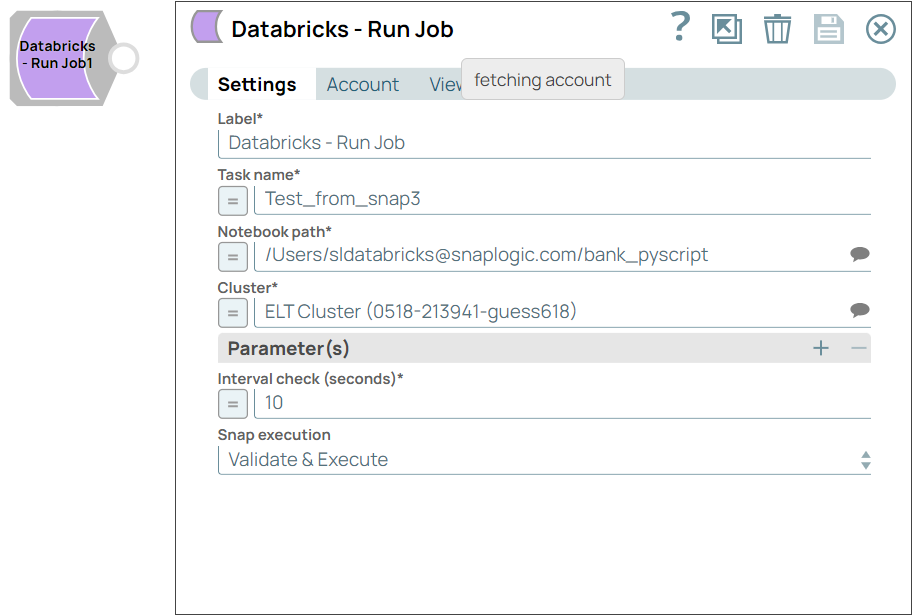
| Label | String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Databricks - Run Job Example: Run Job |
| Task name | String/Expression | Required. Specify the name of the task to
perform the job. Default value: N/A Example: Test username and password |
| Notebook path | String/Expression/ Suggestion | Required. Specify the path of the saved
notebook that will run in this job. Notebook is a web-based interface that allows
you to create, edit, and execute data science and data engineering workflows. Learn more about Databricks notebooks. Default value: N/A Example: /Users/[email protected]/notebook |
| Cluster | String/Expression/ Suggestion | Required. Specify the cluster to run the job
within its environment. Default value: N/A Example: Code Ammonite - Shared Compute Cluster - V2 |
| Parameters | Use this field set to specify the parameters to run the job. | |
| Key | String/Expression | Required. Specify the parameter key. Default value: N/A Example: Age |
| Value | String/Expression | Required. Specify the parameter value. Default value: N/A Example: 35 |
| Interval check (seconds) | Integer/Expression | Required. Specify the number of seconds to
wait before checking the status of the task. Default value: 10 Example: 15 |
| Snap execution | Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Example: Validate & Execute |