


Cassandra - Select
Overview
This Snap allows you to fetch data from a Cassandra database by providing a table name and configuring the connection. The Snap produces the records from the database on its output view which can then be processed by a downstream Snap. Limit and offset are not supported by Cassandra JDBC driver.
Queries produced by the Snap have an equivalent format: Better Code Block.
 Transform-type Snap
Transform-type Snap Works in Ultra Tasks
Works in Ultra Tasks
Prerequisites
Validated Cassandra account, verified network connectivity to Cassandra server and port, and the Cassandra server running.
Limitations
- The Cassandra-Execute Snap using Apache Cassandra V3 does not support
$$as an escape character for enclosing string input, as$is a reserved character for variable substitution in SnapLogic. - The Cassandra Snap Pack does not support the following data types introduced in Apache
Cassandra V3.x, as the underlying SnapLogic JDBC driver is designed to work with Apache
Cassandra V2.1:
-
DateRange
-
Duration
- Geo-spatial data types such as Point, Polygon and LineString
-
-
Create a table containing a map whose key is a timestamp:
CREATE COLUMNFAMILY t (userid text PRIMARY KEY, todo map<timestamp, text>); -
Insert values into the newly-created table.
INSERT INTO t (userid, todo) VALUES ('a', {'2013-09-22T12:01:00.000+0000': 'text'}); Once the insert operation succeeds, query the map column:SELECT userid, todo FROM t;
The Snap displays the following exception:
com.datastax.driver.core.exceptions.CodecNotFoundException:
Codec not found for requested operation: [timestamp <->
java.sql.Timestamp]Known issues
The Cassandra Select Snap supports inet Data Type that stores the IP address values. Upon validation, the Snap must display a blank space followed by the corresponding IP address value in its output view, which is the expected behavior. But, in the 4.24 Release, this Snap incorrectly displays empty string as null for inet Data Type followed by the IP address value in its output view.
Snap views
| View | Description | Examples of upstream and downstream Snaps |
|---|---|---|
| Input | This Snap has at most one document input view. If the input view is defined,
then the where clause can substitute incoming values for a given expression. Data, if any, to be used to narrow the selection of data coming from Cassandra. |
|
| Output | This Snap has at most two document output views. Data of interest from Cassandra. |
|
| Error |
Error handling is a generic way to handle errors without losing data or failing the Snap execution. You can handle the errors that the Snap might encounter when running the pipeline by choosing one of the following options from the When errors occur list under the Views tab. The available options are:
Learn more about Error handling in Pipelines. |
|
Snap settings
- Expression icon (
 ): Allows using pipeline parameters to set field
values dynamically (if enabled). SnapLogic Expressions are not supported. If
disabled, you can provide a static value.
): Allows using pipeline parameters to set field
values dynamically (if enabled). SnapLogic Expressions are not supported. If
disabled, you can provide a static value. - SnapGPT (
 ): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more.
): Generates SnapLogic Expressions
based on natural language using SnapGPT. Learn
more. - Suggestion icon (
 ): Populates a
list of values dynamically based on your Snap configuration.
You can select only one attribute at a time using the icon.
Type into the field if it supports a comma-separated list of values.
): Populates a
list of values dynamically based on your Snap configuration.
You can select only one attribute at a time using the icon.
Type into the field if it supports a comma-separated list of values. - Upload
 : Uploads files. Learn more.
: Uploads files. Learn more.
| Field / Field set | Type | Description |
|---|---|---|
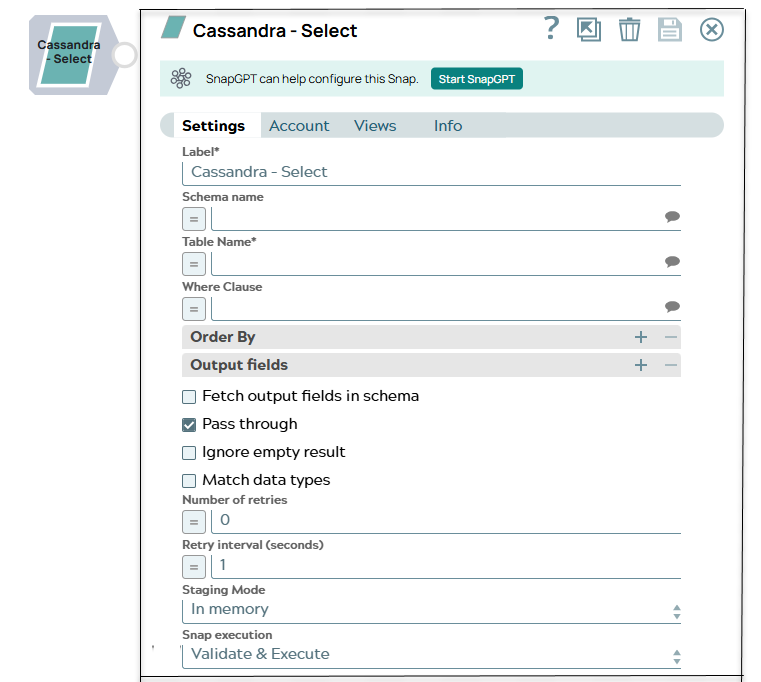
| Label | String | Required. Specify a unique name for the Snap. Modify this to be more appropriate, especially if more than one of the same Snaps is in the pipeline. Default value: Cassandra - Select Example: Cassandra - Select |
| Schema name | String/Expression/ Suggestion | The database schema name. In case it is not defined, then the suggestion for the table name will retrieve all tables names of all schemas. The property is suggestible and will retrieve available database schemas during suggest values. Default value: None. Example: SYS |
| Table Name | String/Expression/ Suggestion | Required. The name of table to execute select query
on. Default value: None. Example: People |
| Where clause | String/Expression/ Suggestion |
WHERE clause of SELECT statement. The value to be used in the WHERE clause will
be used here. Document value substitutions (such as $person.firstname with the
value found in the incoming document at the path) can also be used as needed. The
"=" will not need to be checked when using document value substitutions unless
using expression language.
Warning:
Using expressions that join strings together to create SQL queries or conditions has a potential SQL injection risk and is hence unsafe. Ensure that you understand all implications and risks involved before using concatenation of strings with '=' Expression enabled. Warning: The Where clause property does not support
passing Pipeline parameters or passing upstream parameters. Examples: Without using expressions
Using expressions
Default value: None. |
| Order by: | ||
| Column names | String/Expression/ Suggestion |
Enter in the columns in the order in which you want to order by. The default database sort order will be used. Default value: None. Example: name |
| Output fields | ||
| Output field | String/Expression/ Suggestion | Enter or select output field names for SQL SELECT statement. To select all
fields, leave it at default. Example: email, address, first, last, etc. Default value: None. |
| Fetch Output Fields In Schema | Checkbox | Select this check box to include only the selected fields or columns in the
Output Schema (second output view). If you do not provide any Output fields,
all the columns are visible in the output. If you provide output fields, we recommend
you to select Fetch Output Fields In Schema check box. Default status: Deselected |
| Pass through | Checkbox |
If checked, the input document will be passed through to the output view under the key 'original'. Default status: Selected |
| Number of retries | Integer/Expression | Specifies the maximum number of attempts to be made to receive a response. The
request is terminated if the attempts do not result in a response. Tip:
If the value is larger than 0, the Snap first downloads the target file into a temporary local file. If any error occurs during the download, the Snap waits for the time specified in the Retry interval and attempts to download the file again from the beginning. When the download is successful, the Snap streams the data from the temporary file to the downstream Pipeline. All temporary local files are deleted when they are no longer needed. Ensure that the local drive has sufficient free disk space to store the temporary local file. Default value: 0 Example: 3 |
| Retry interval (seconds) | Integer/Expression | Specifies the time interval between two successive retry requests. A retry
happens only when the previous attempt resulted in an exception. Example: 10 Default value: 1 |
| Staging mode | Dropdown list | Required when the value in the Number of retries field is greater
than 0.
Specify the location from the following options to store input documents between retries:
|
| Snap execution | Dropdown list |
Choose one of the three modes in
which the Snap executes. Available options are:
Default value: Execute only Example: Validate & Execute |
For the 'Suggest' in the Order by columns and the Output fields properties, the value of the Table name property should be an actual table name instead of an expression. If it is an expression, it will display an error message "Could not evaluate accessor: ..." when the 'Suggest' button is clicked. This is because, at the time the "Suggest" button is clicked, the input document is not available for the Snap to evaluate the expression in the Table name property. The input document is available to the Snap only during the preview or execution time.
Troubleshooting
- Run Cassandra JDBC driver using another JDBC tool to verify syntax and results.